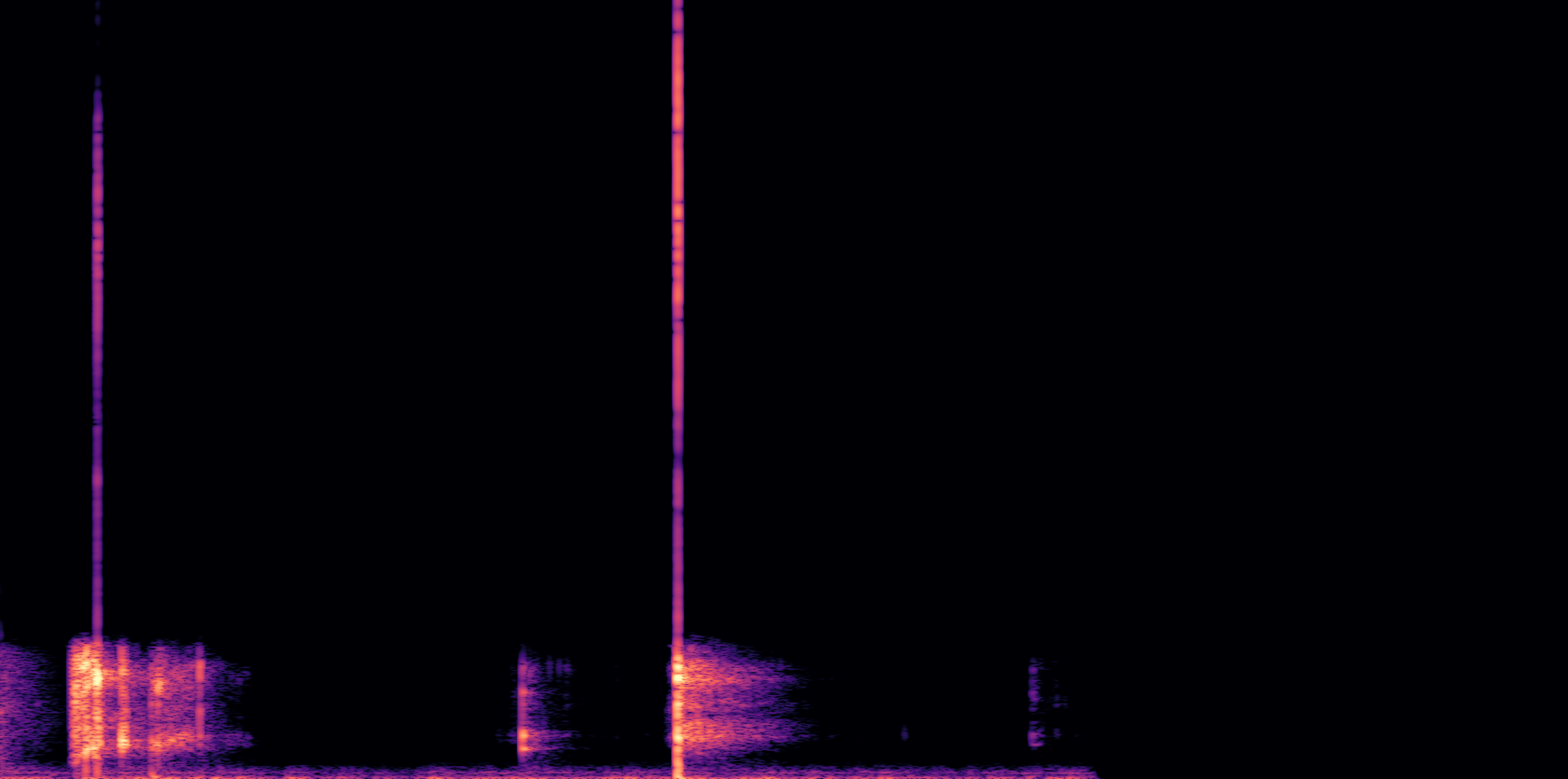
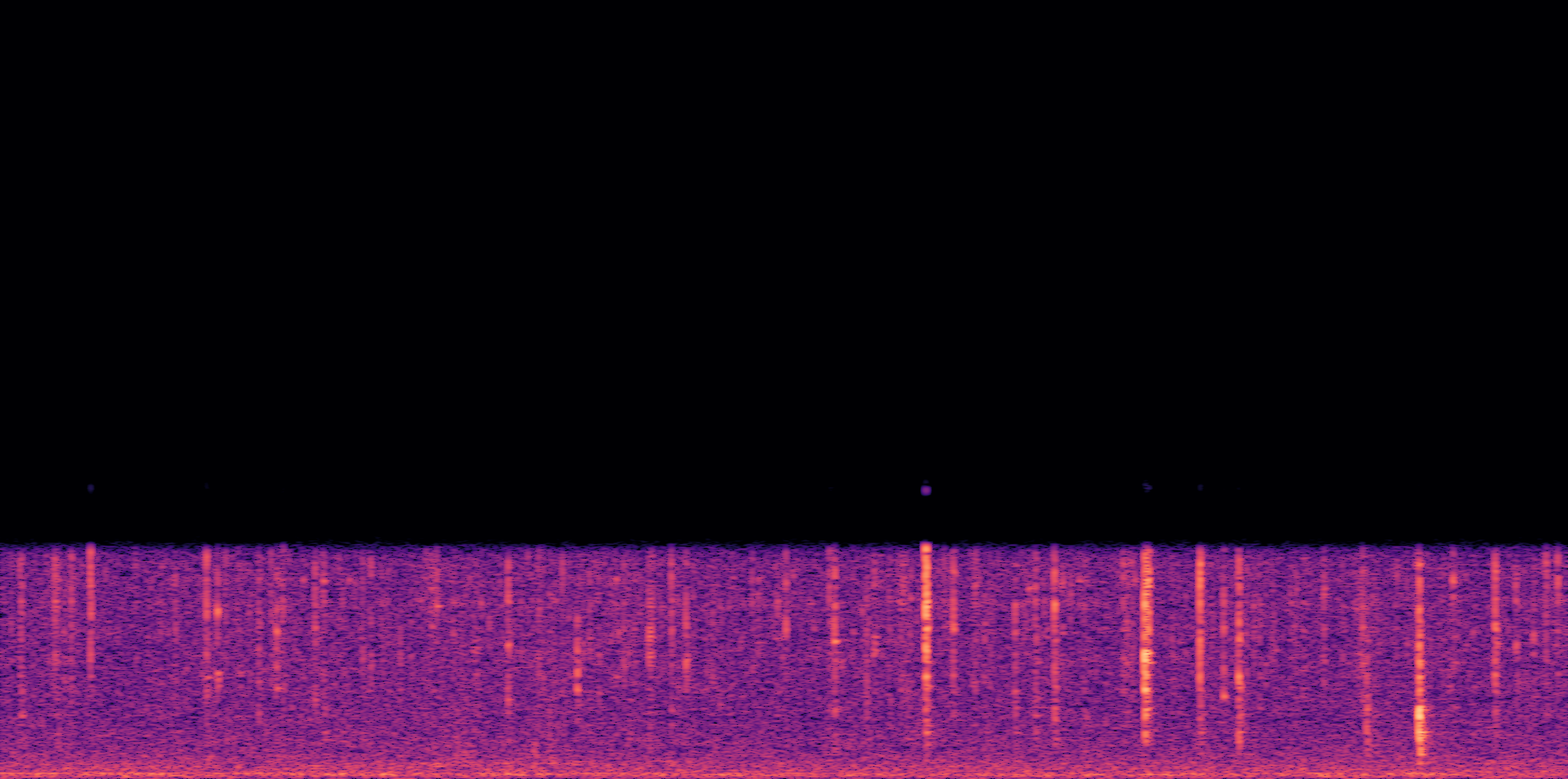
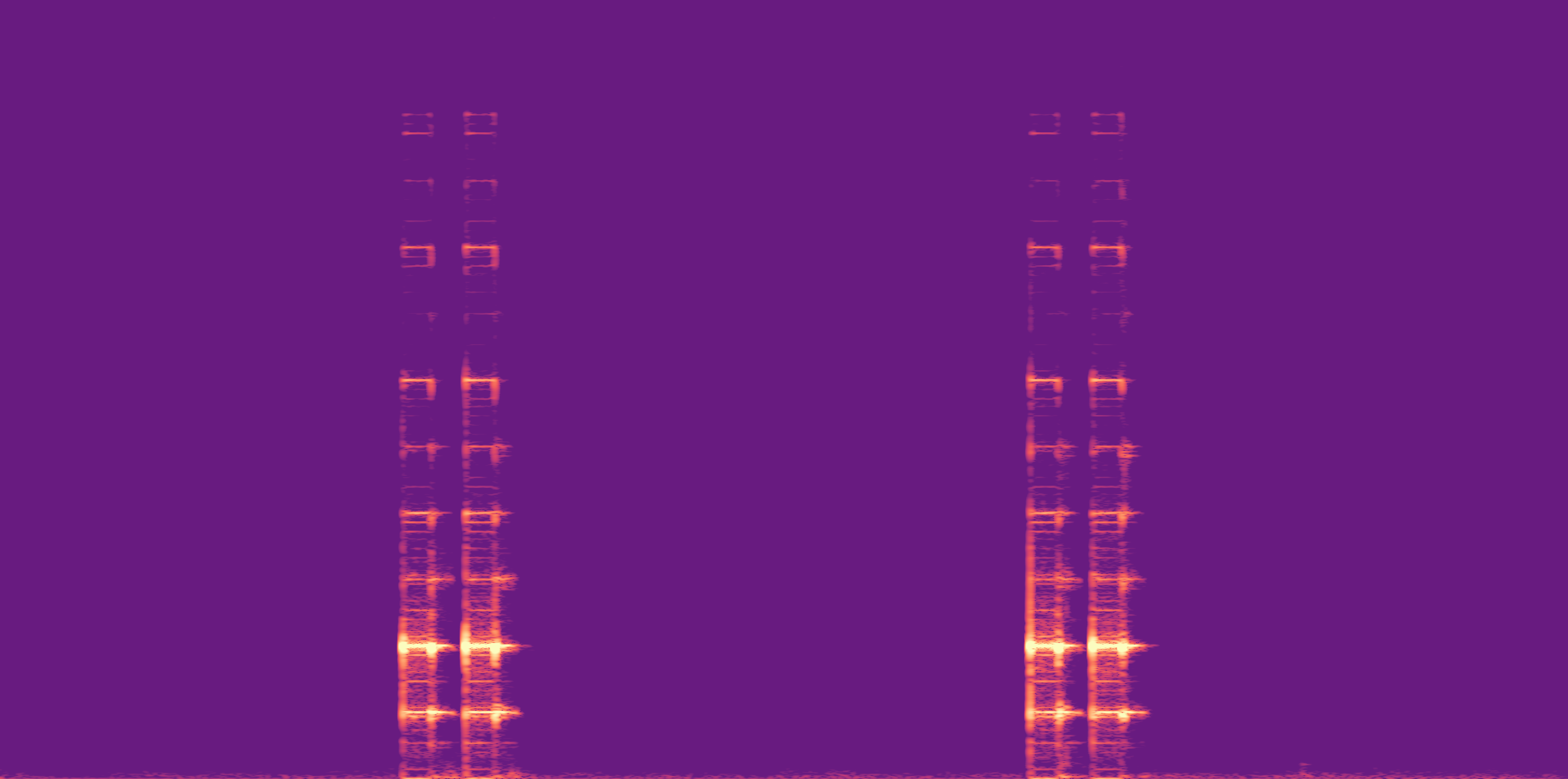
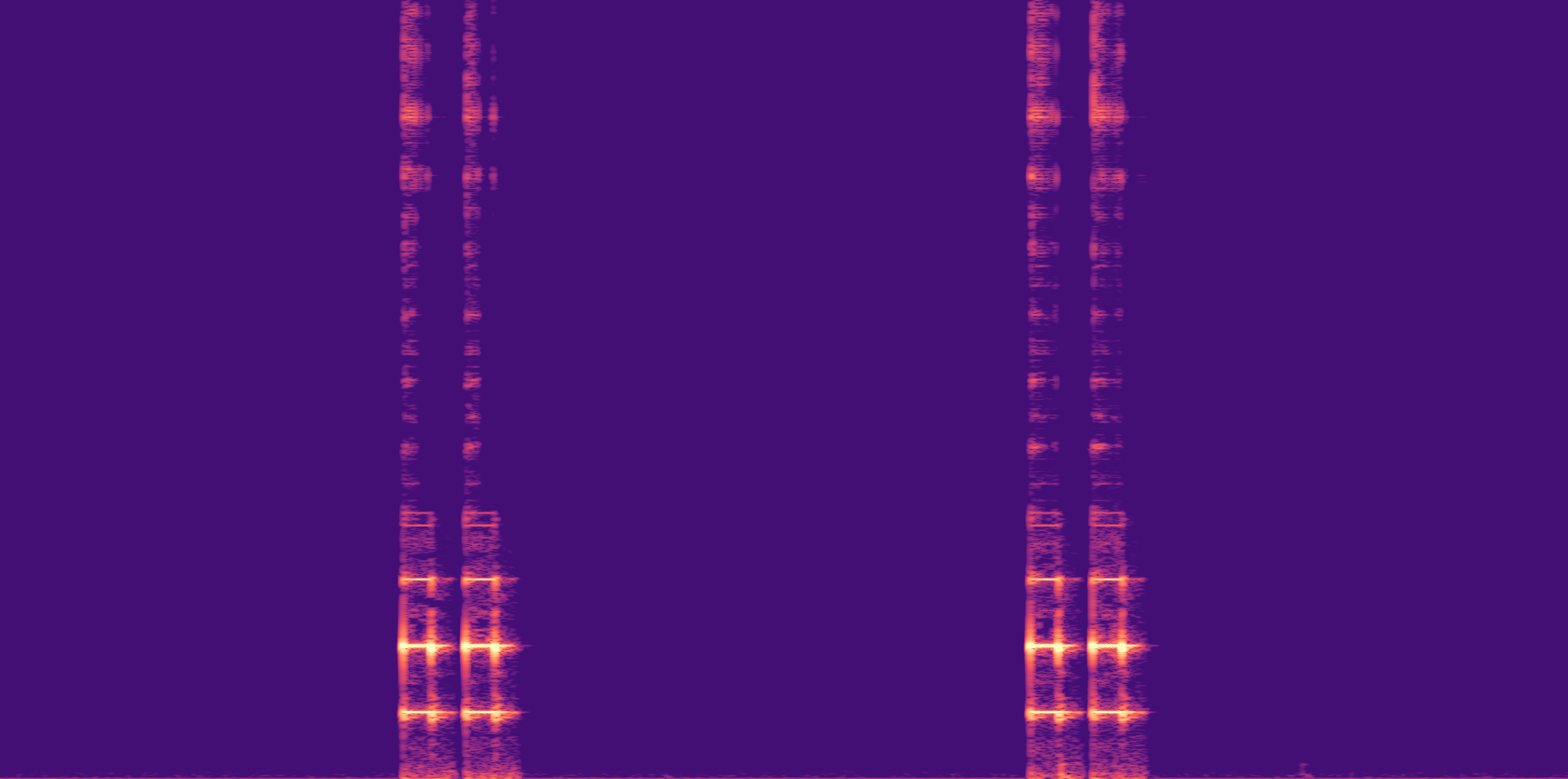
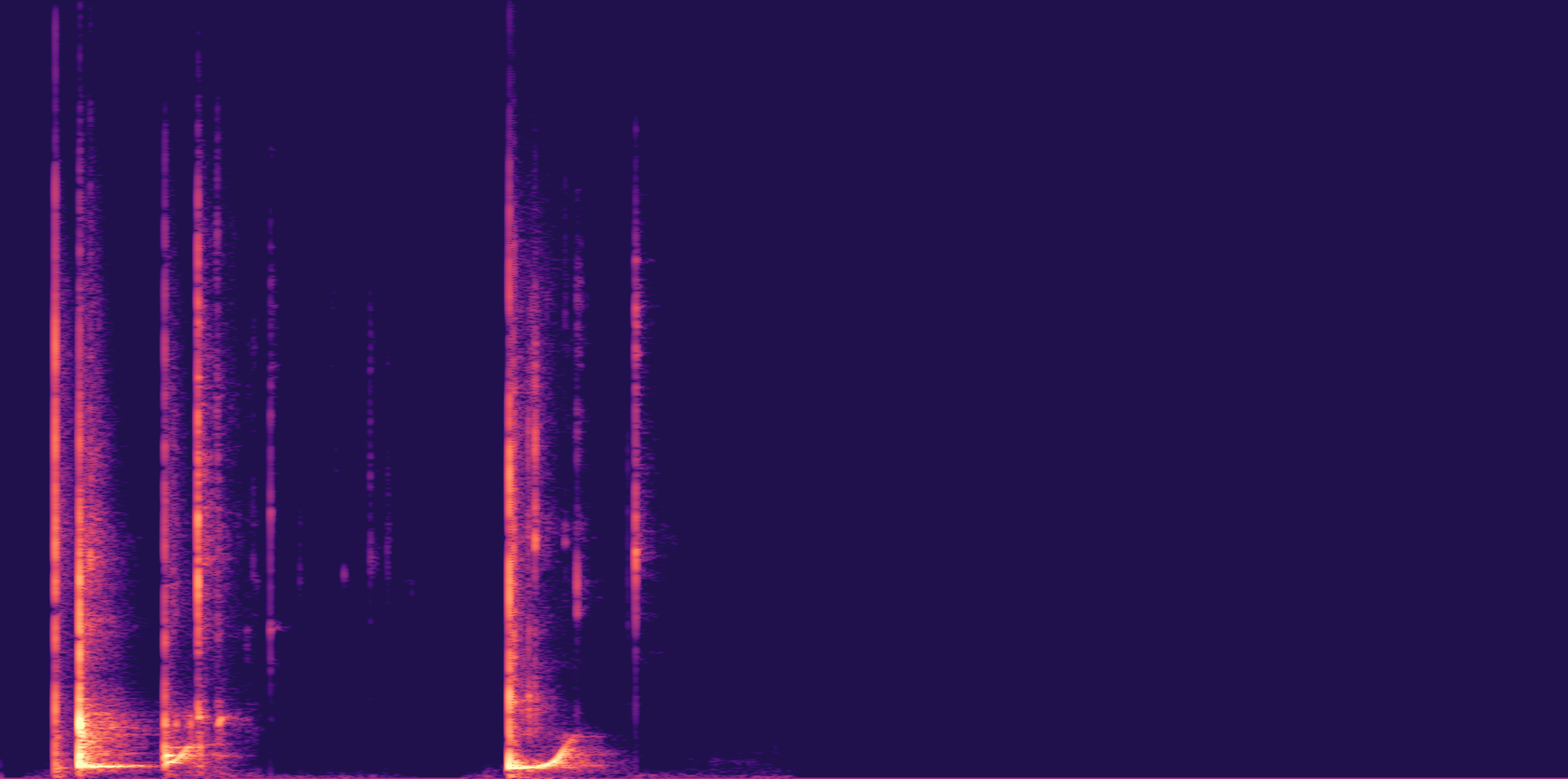
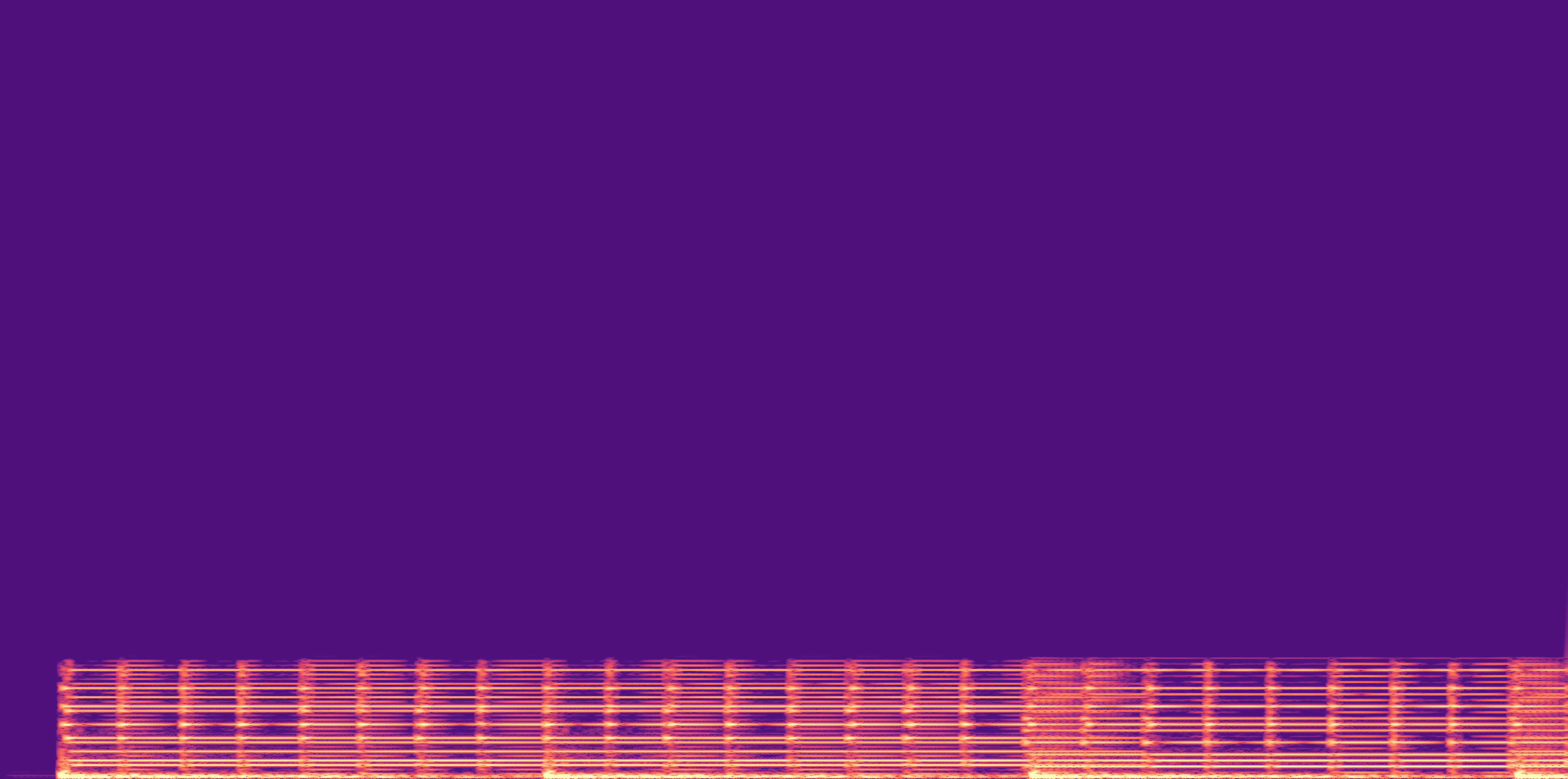
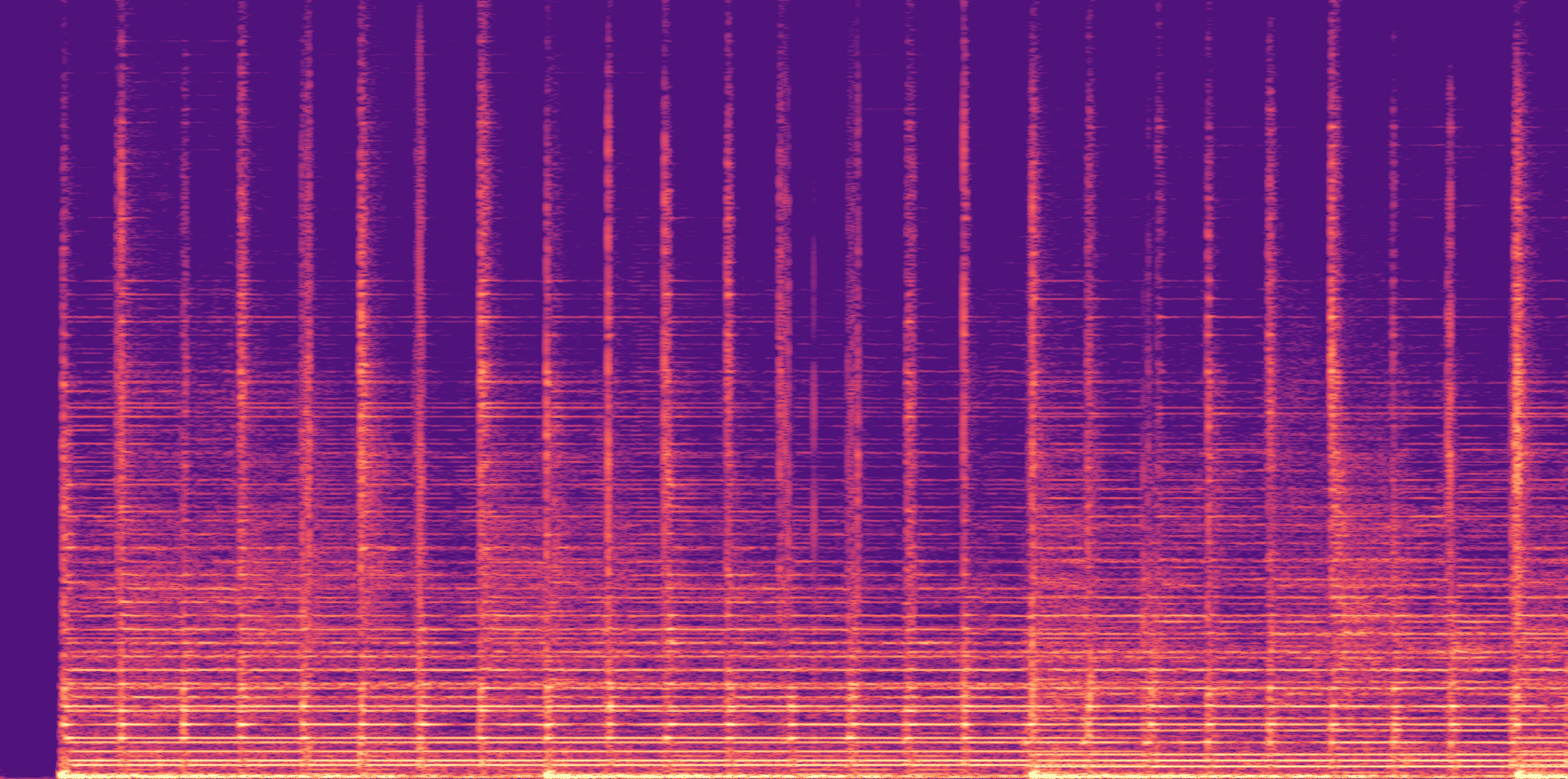
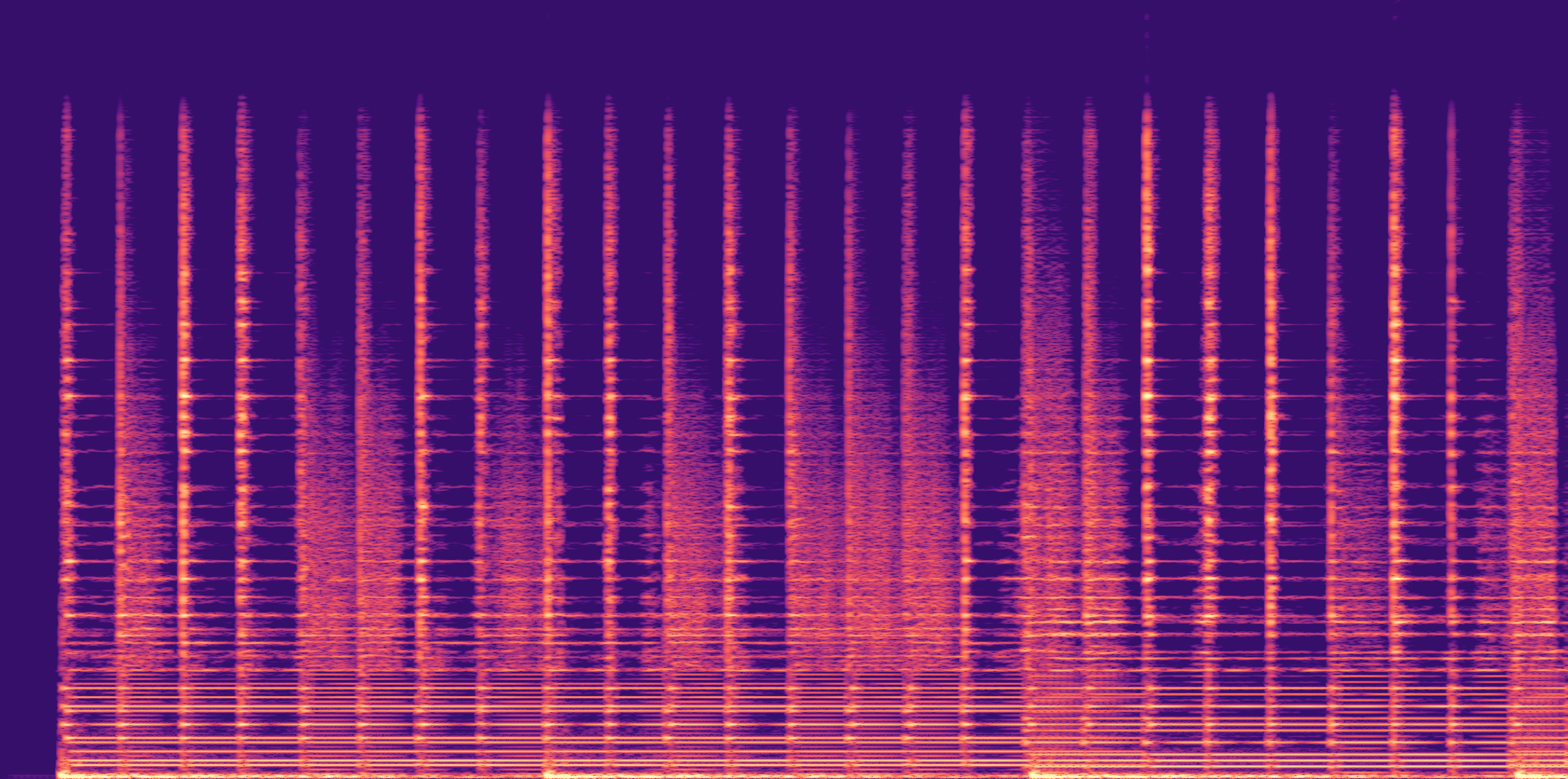
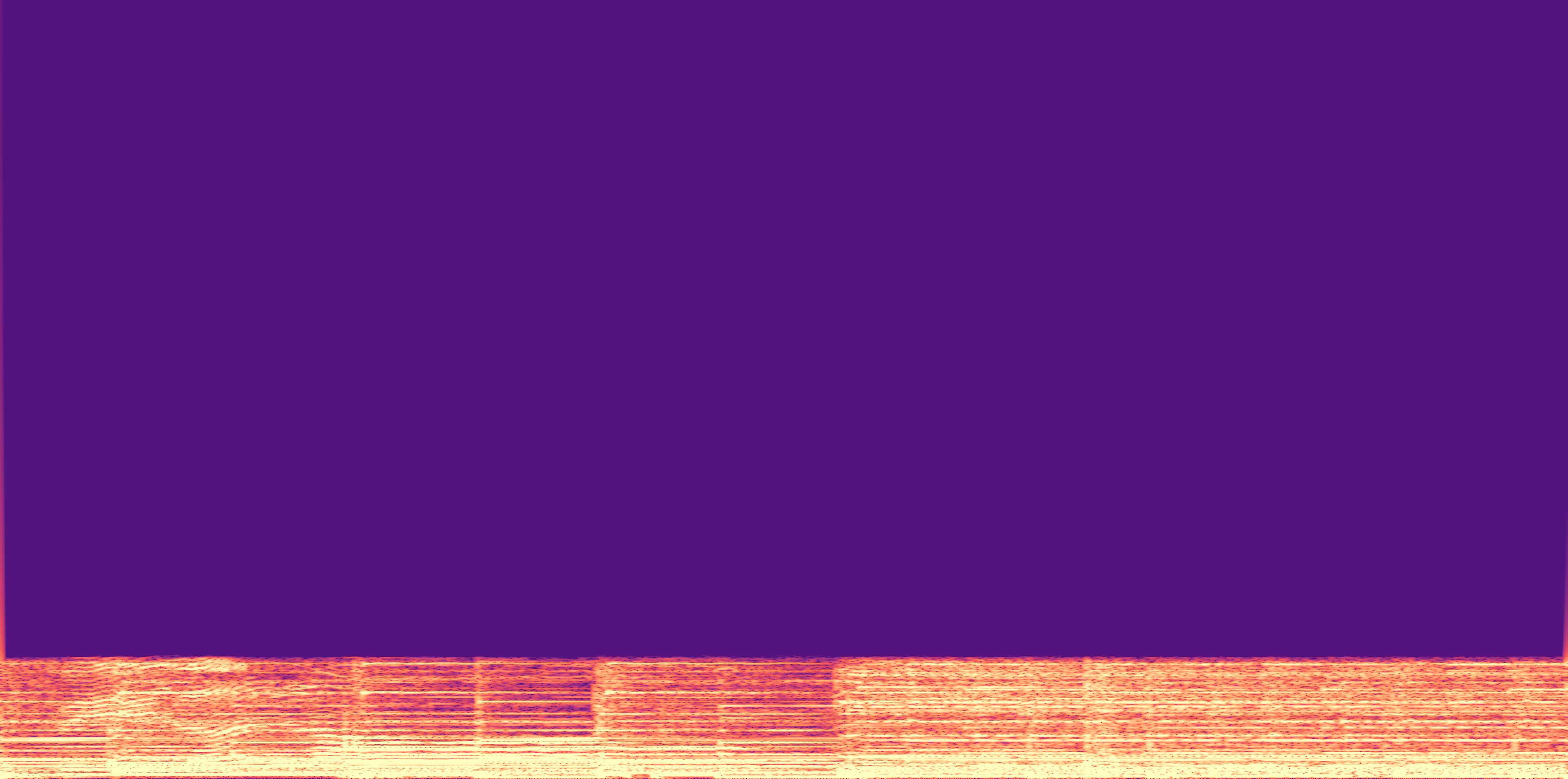
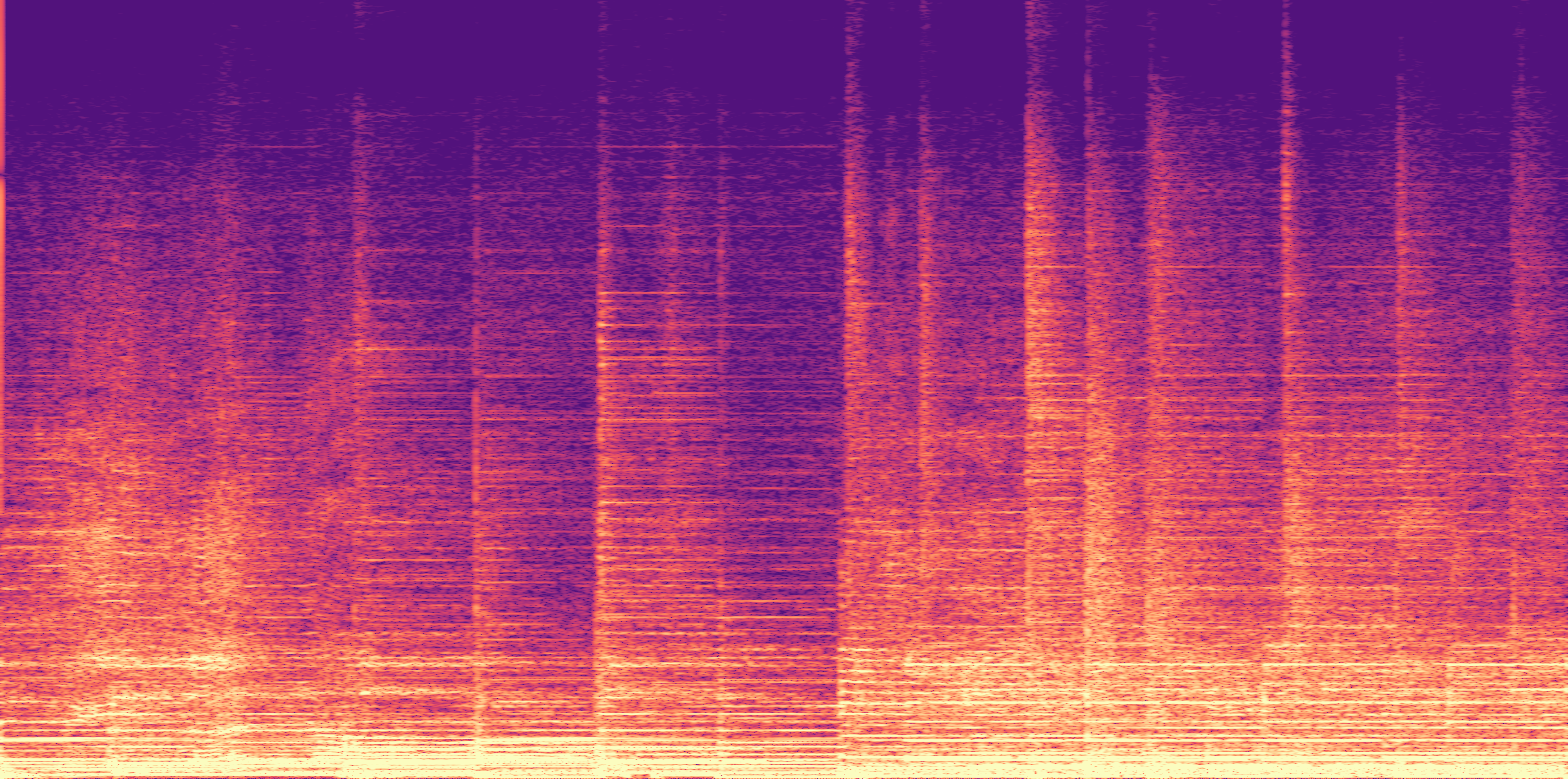
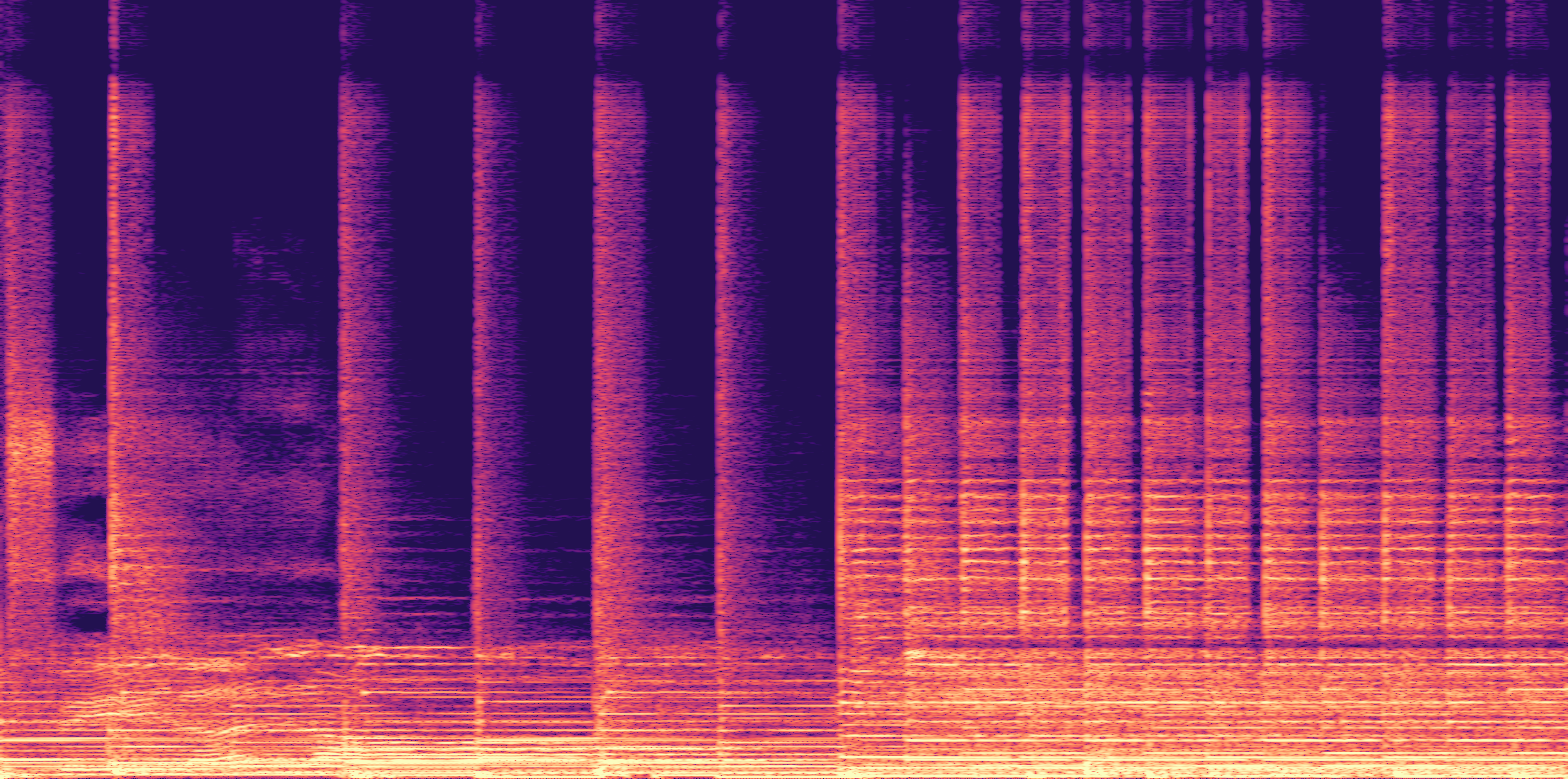
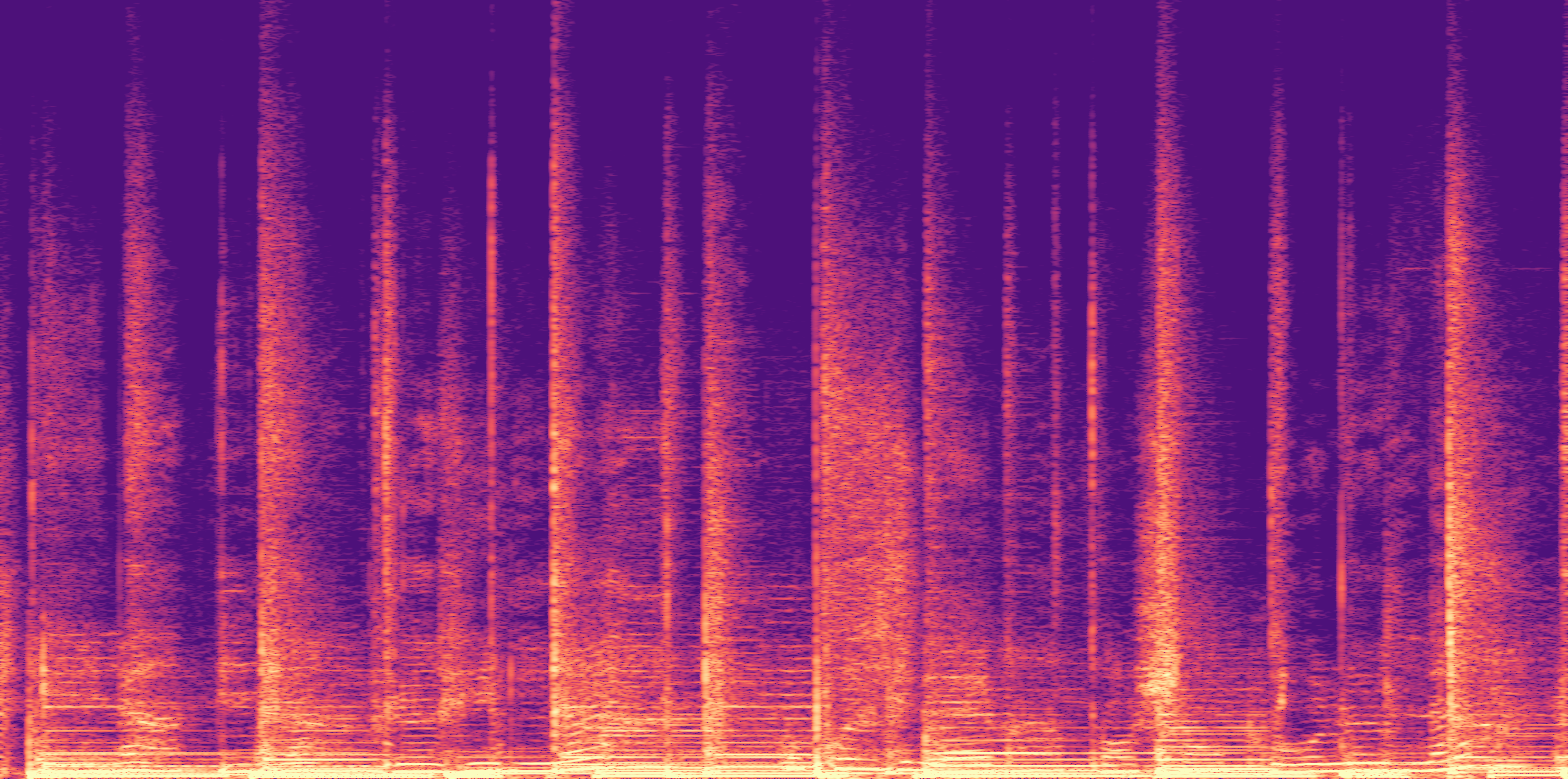
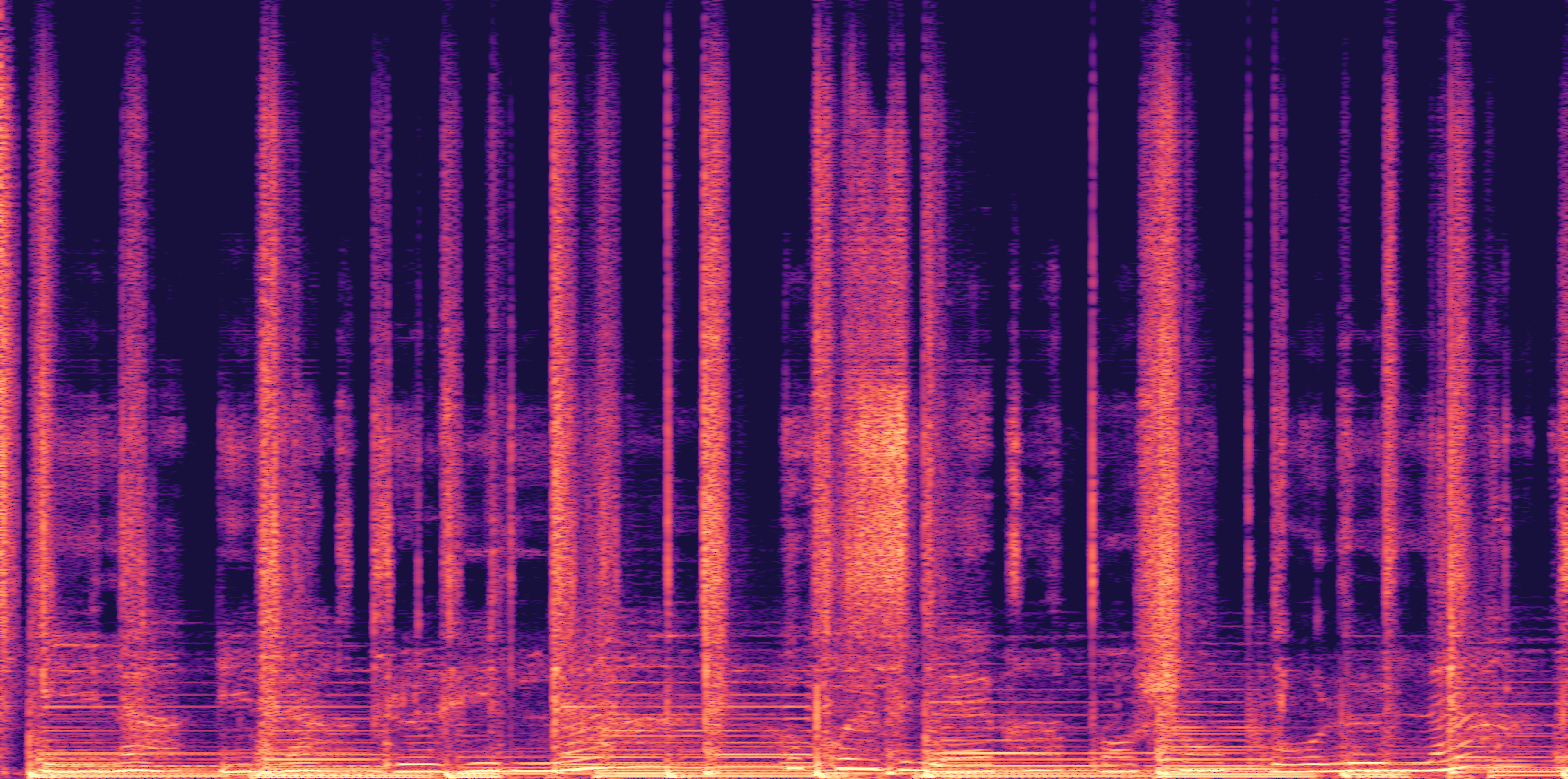
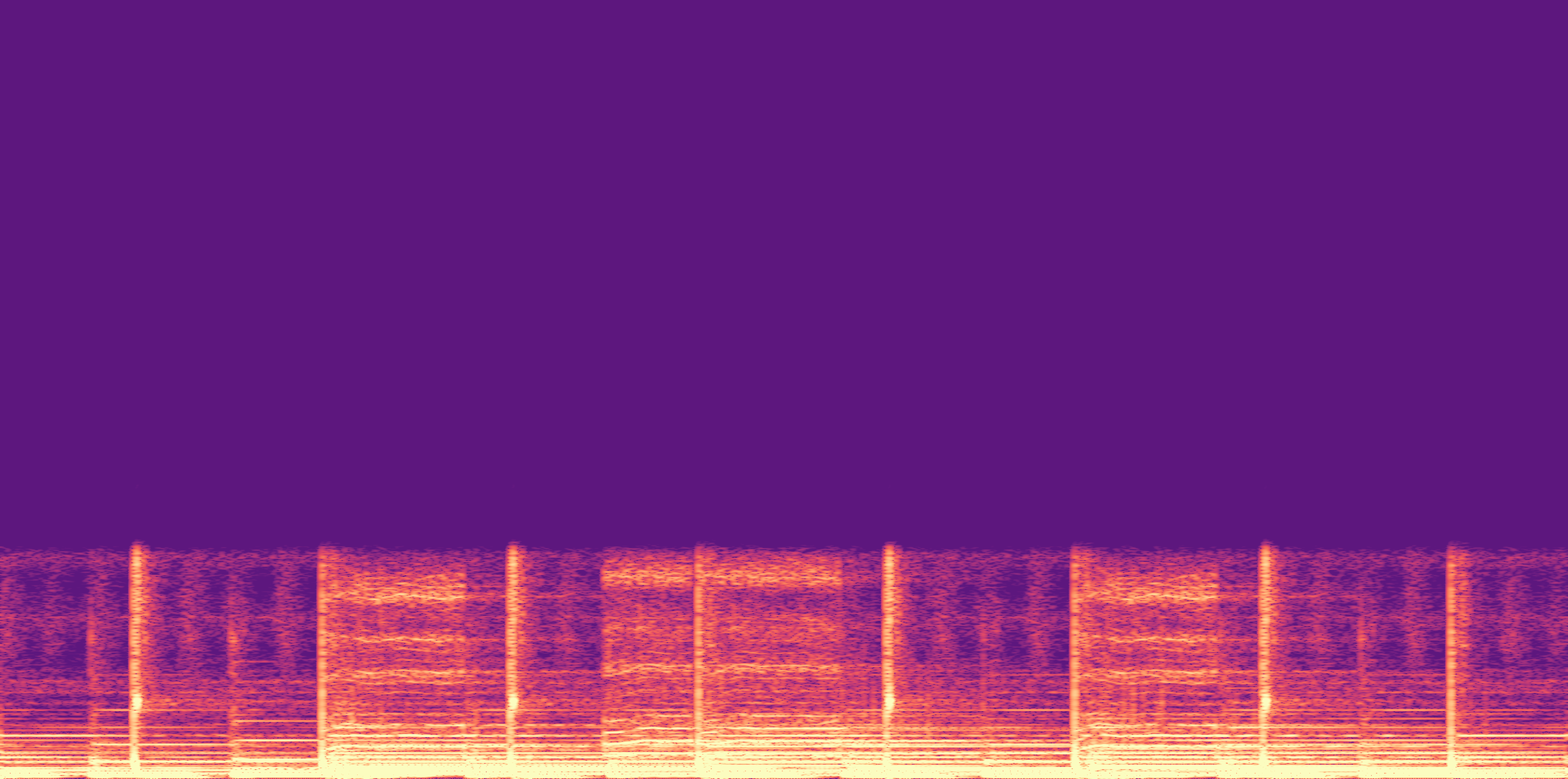
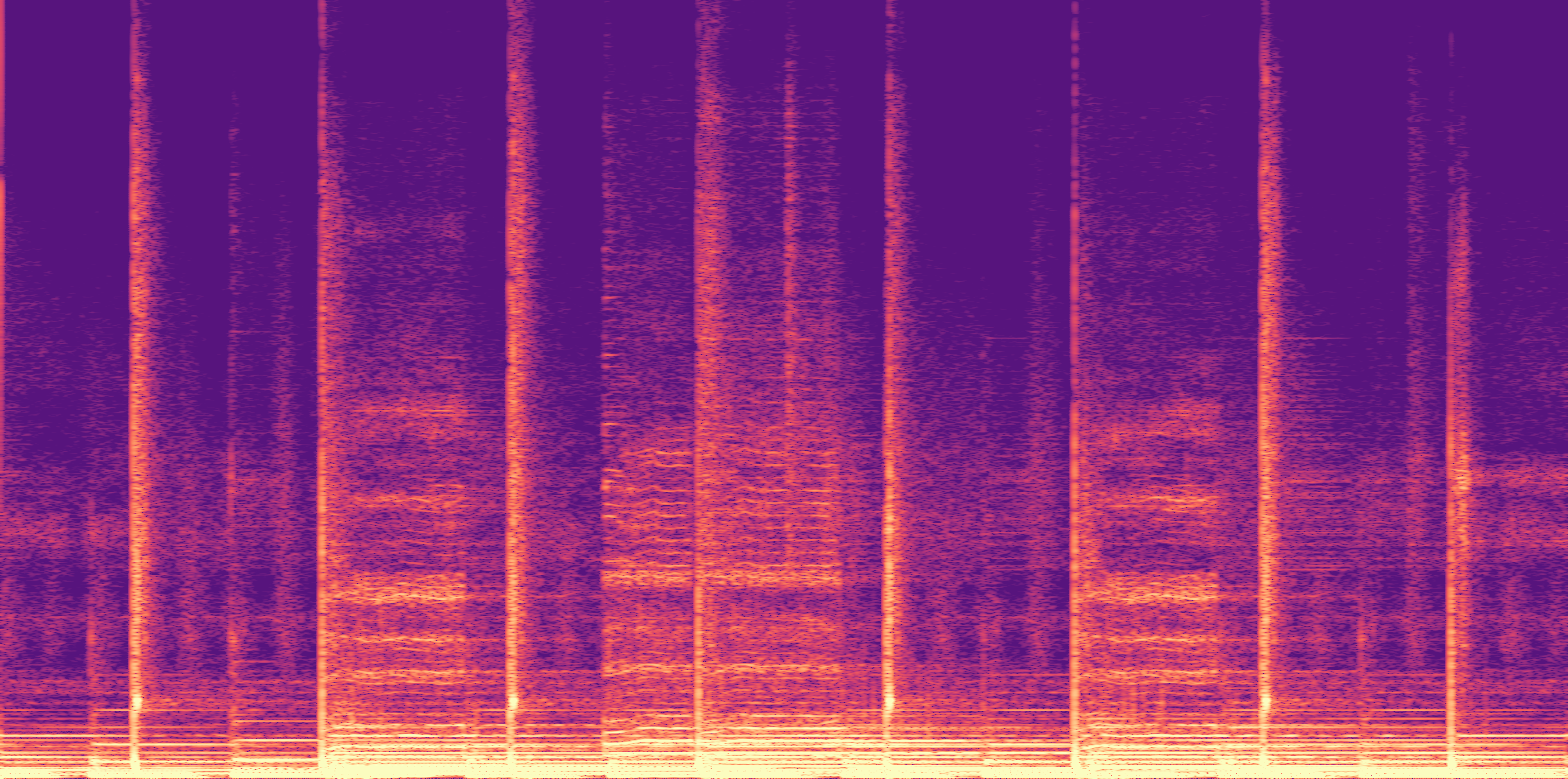
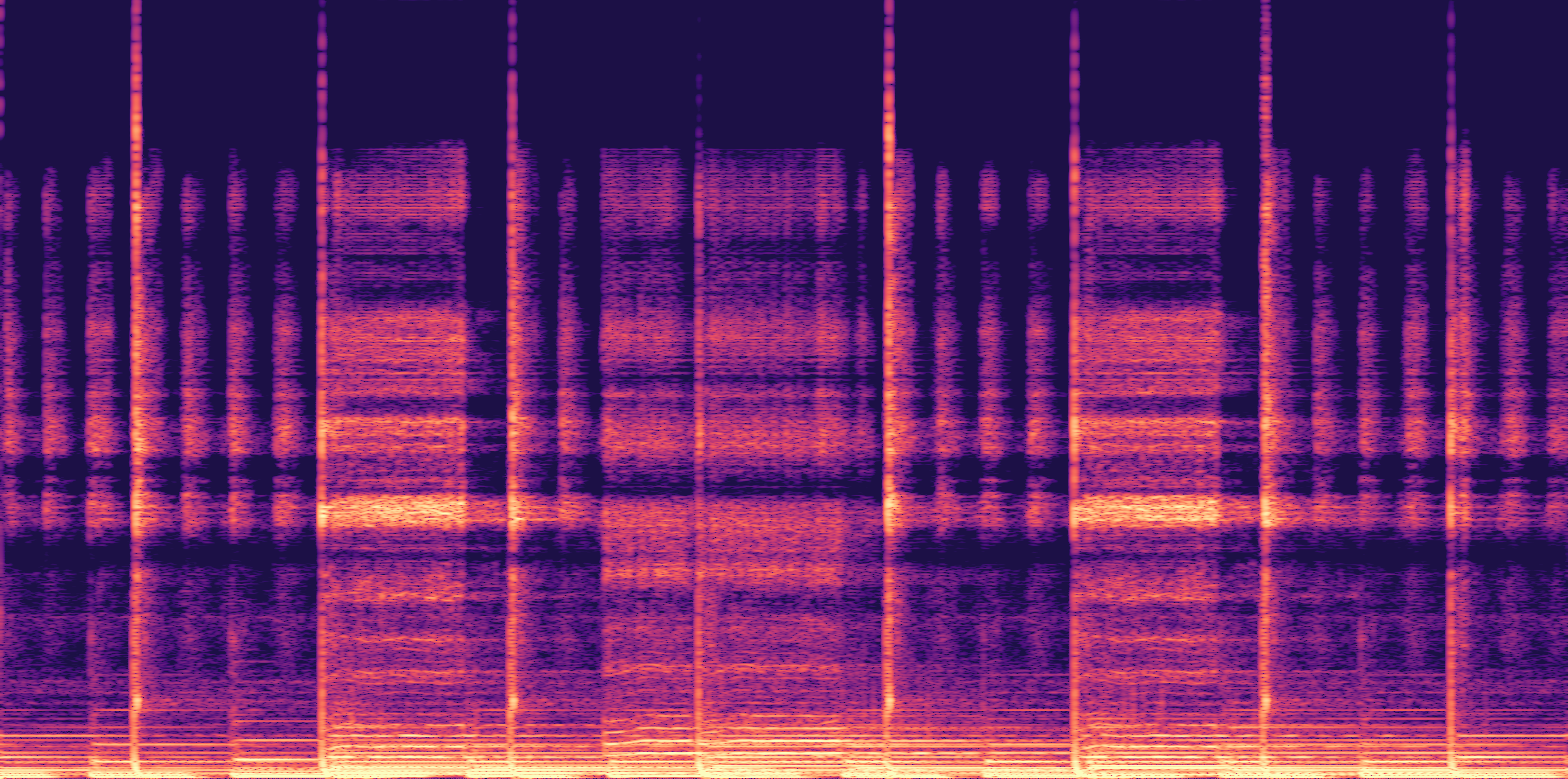
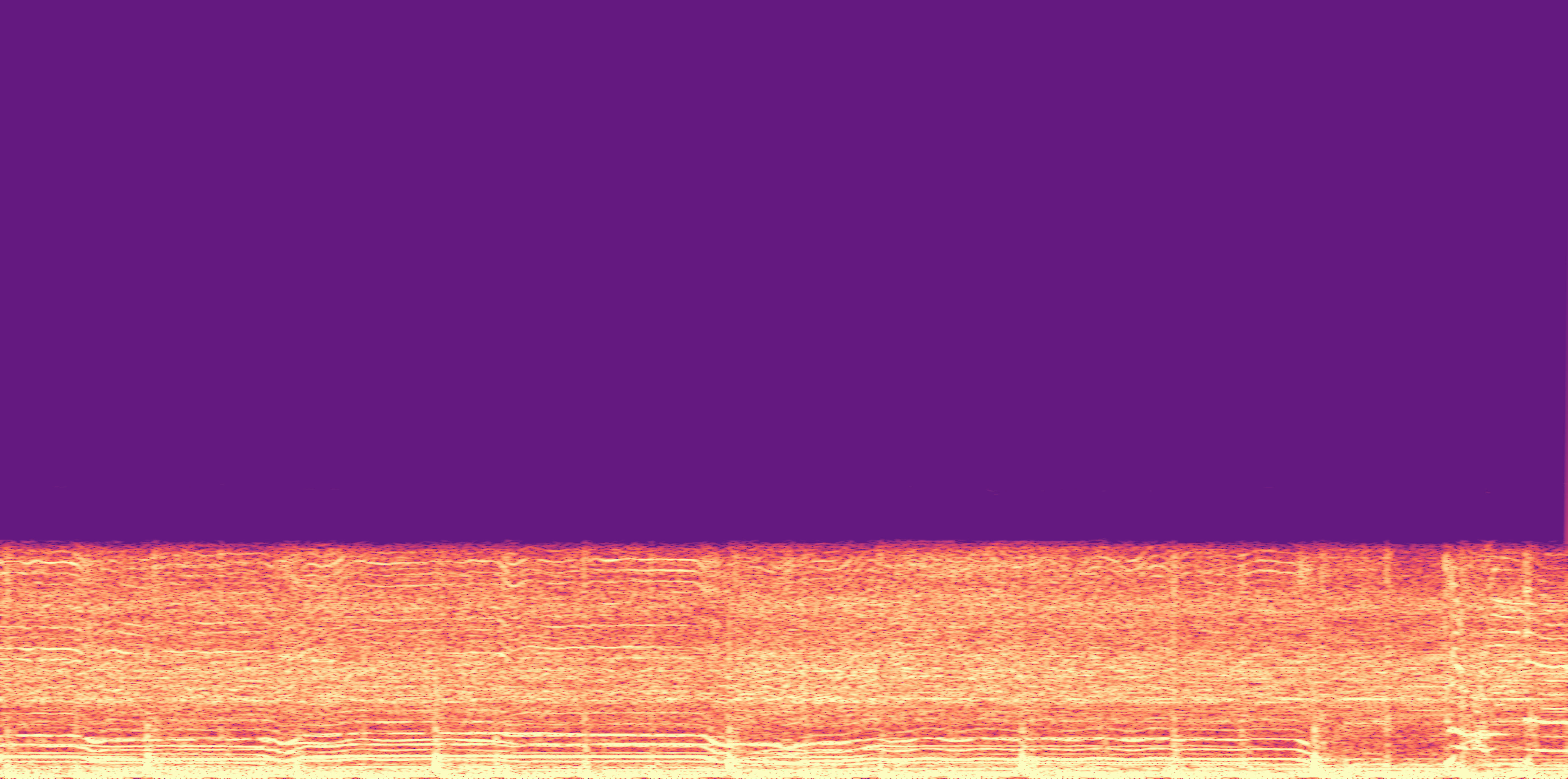
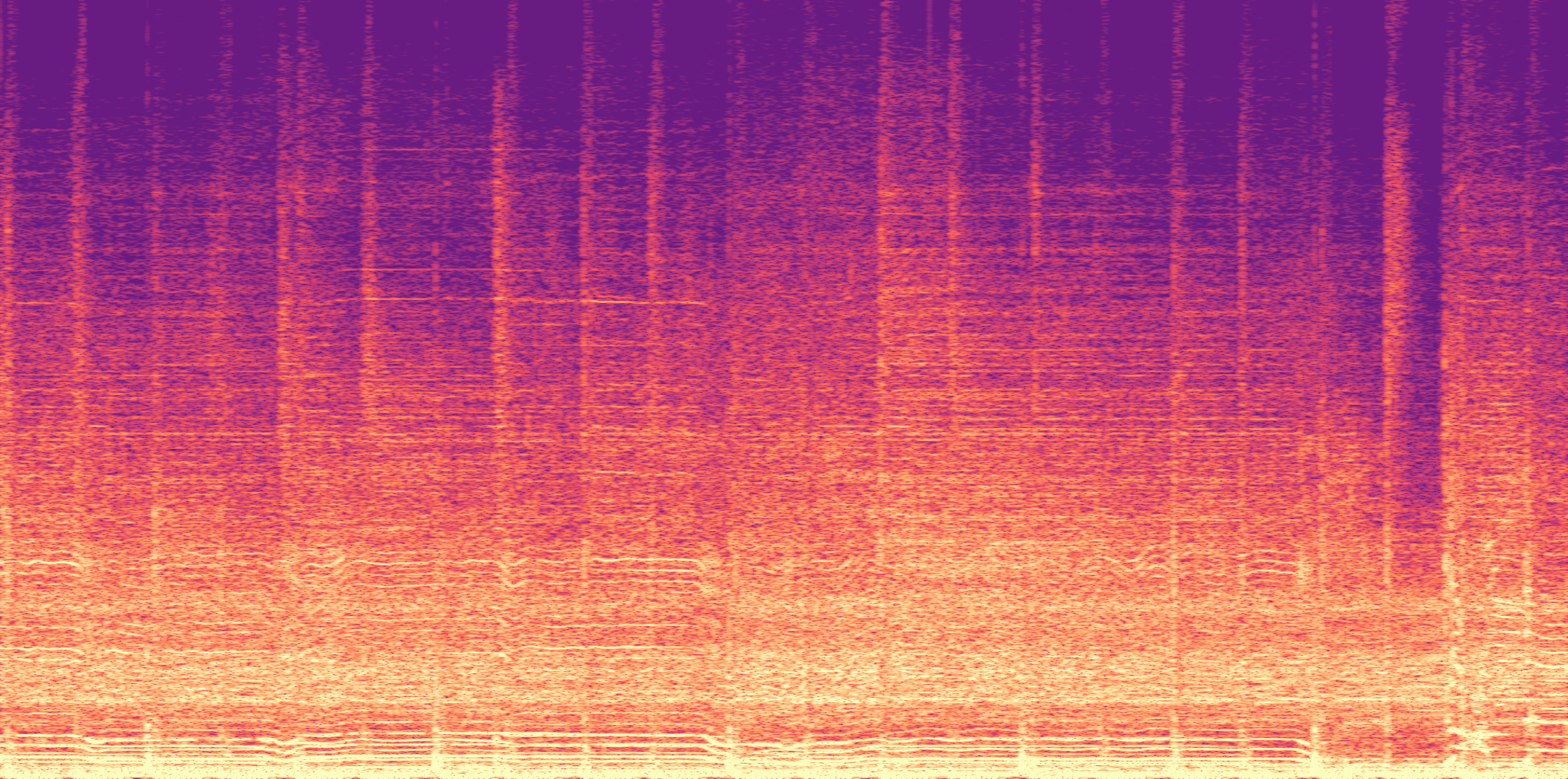
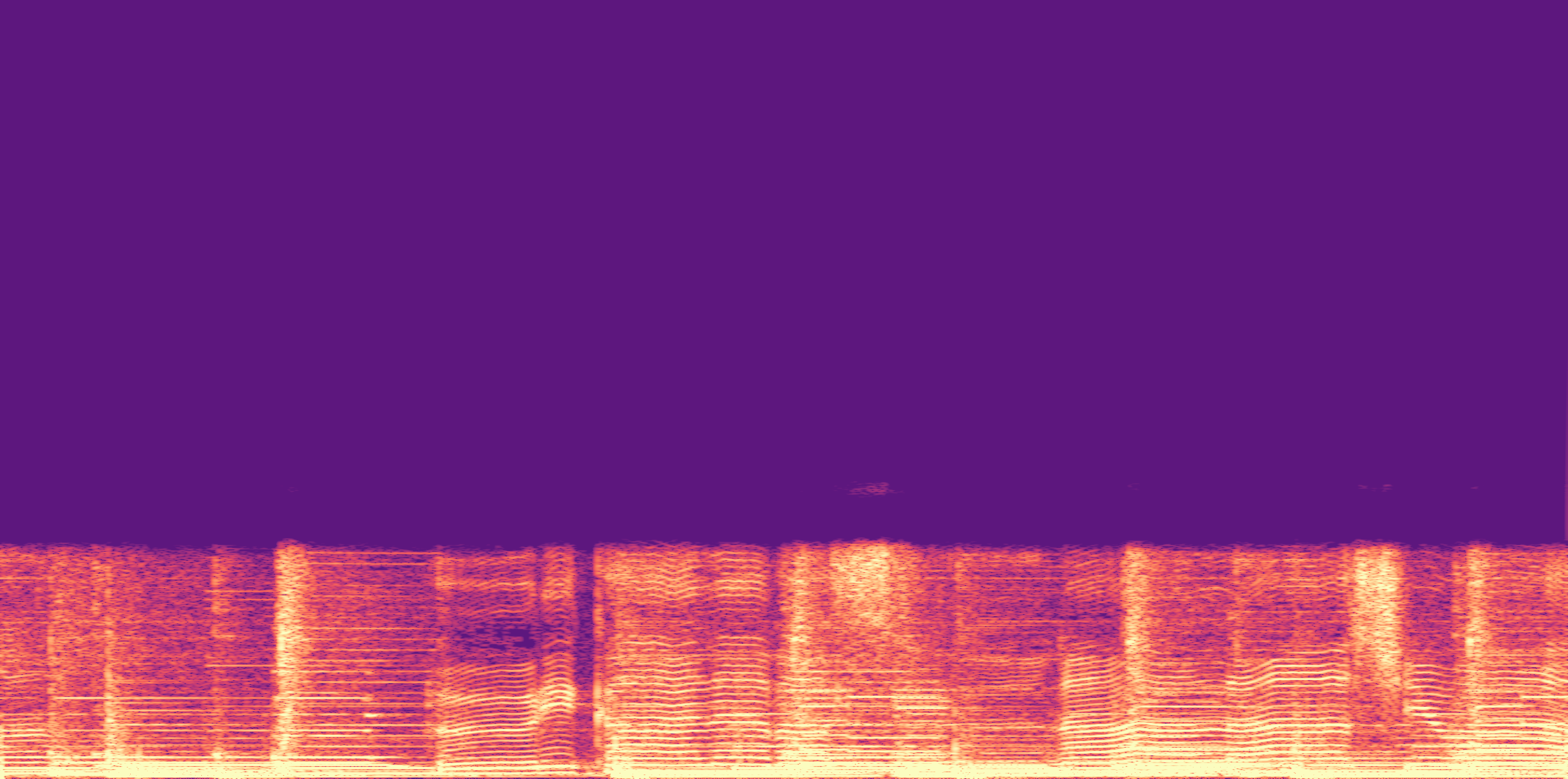
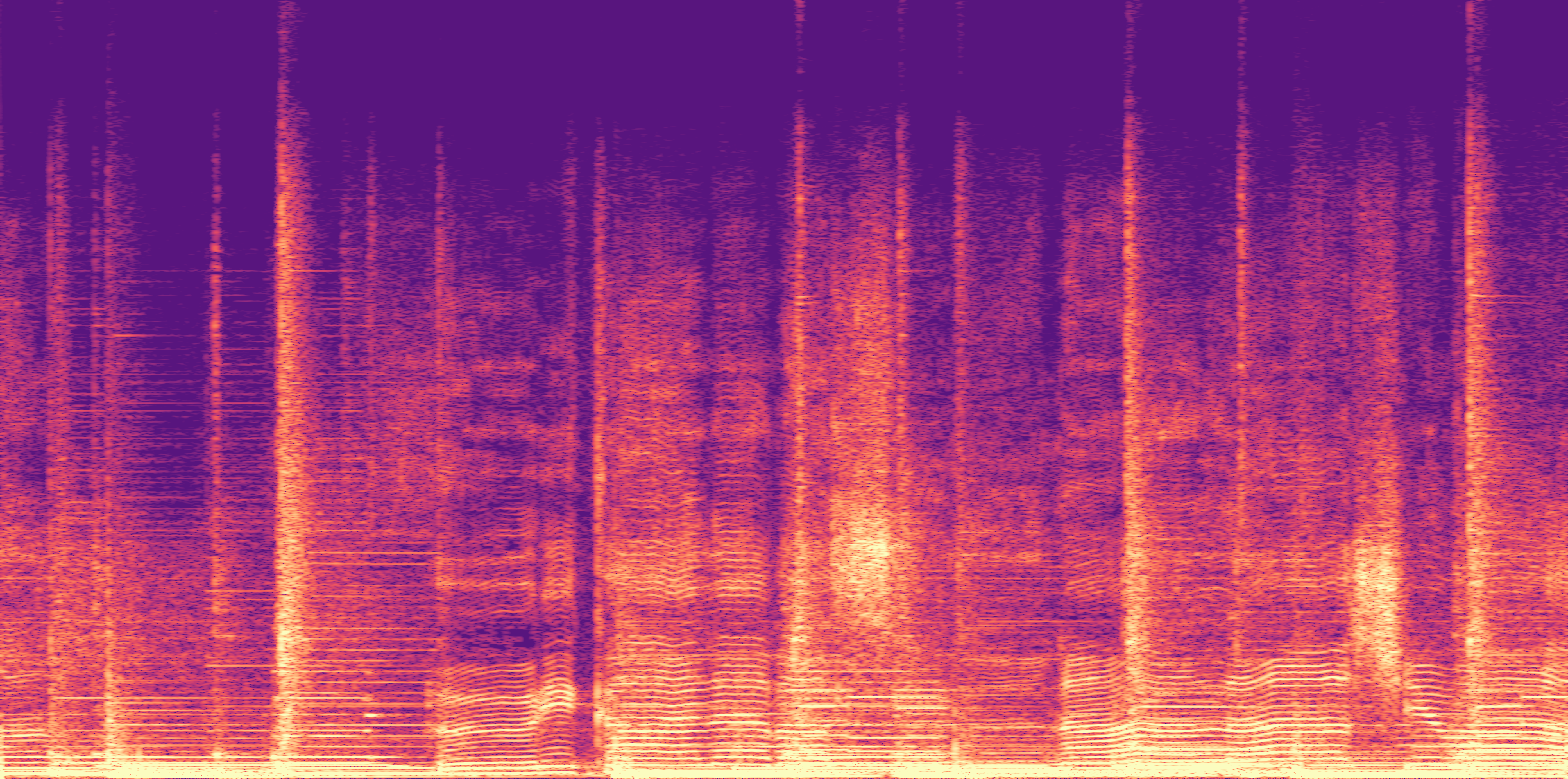
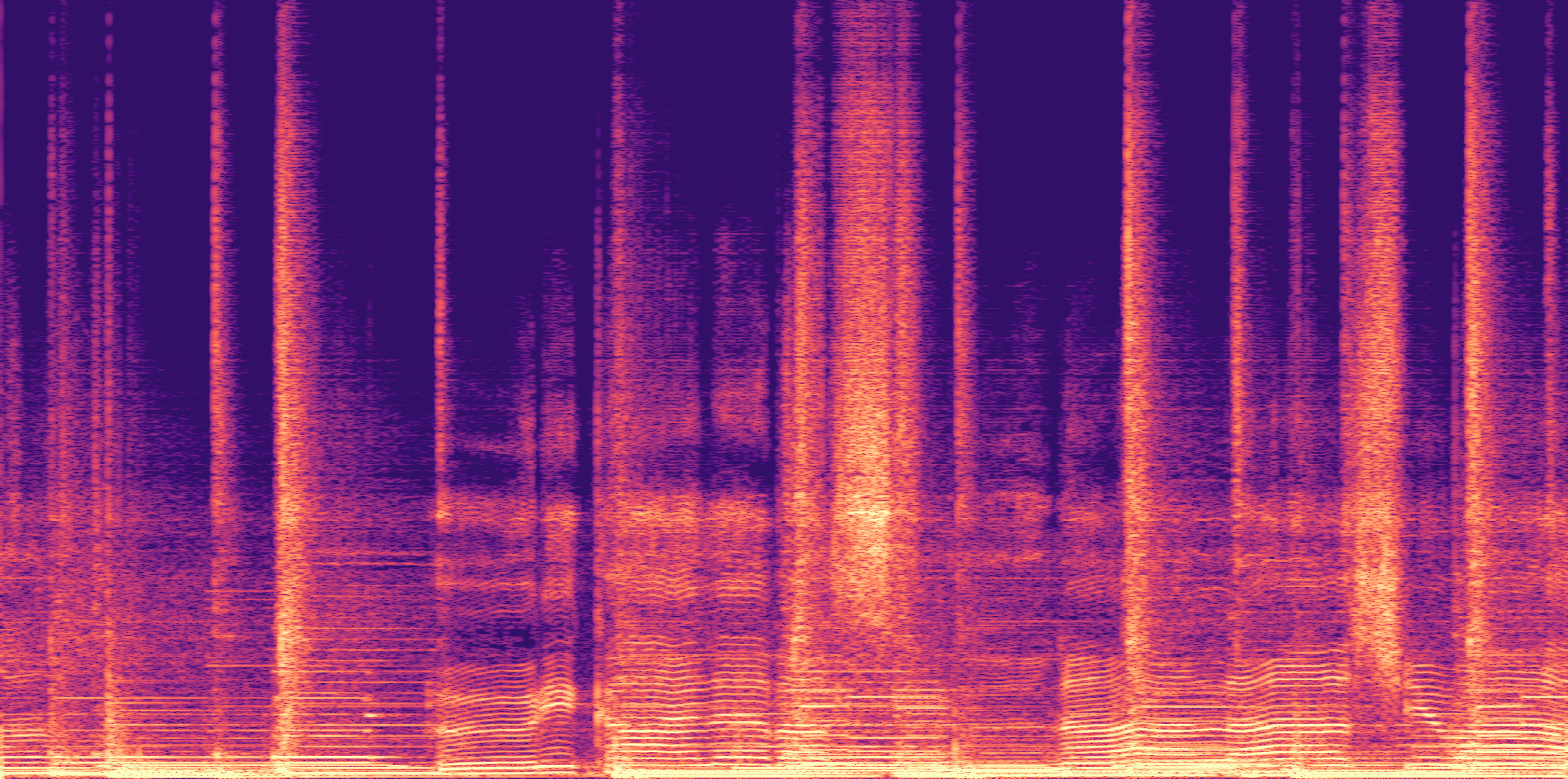
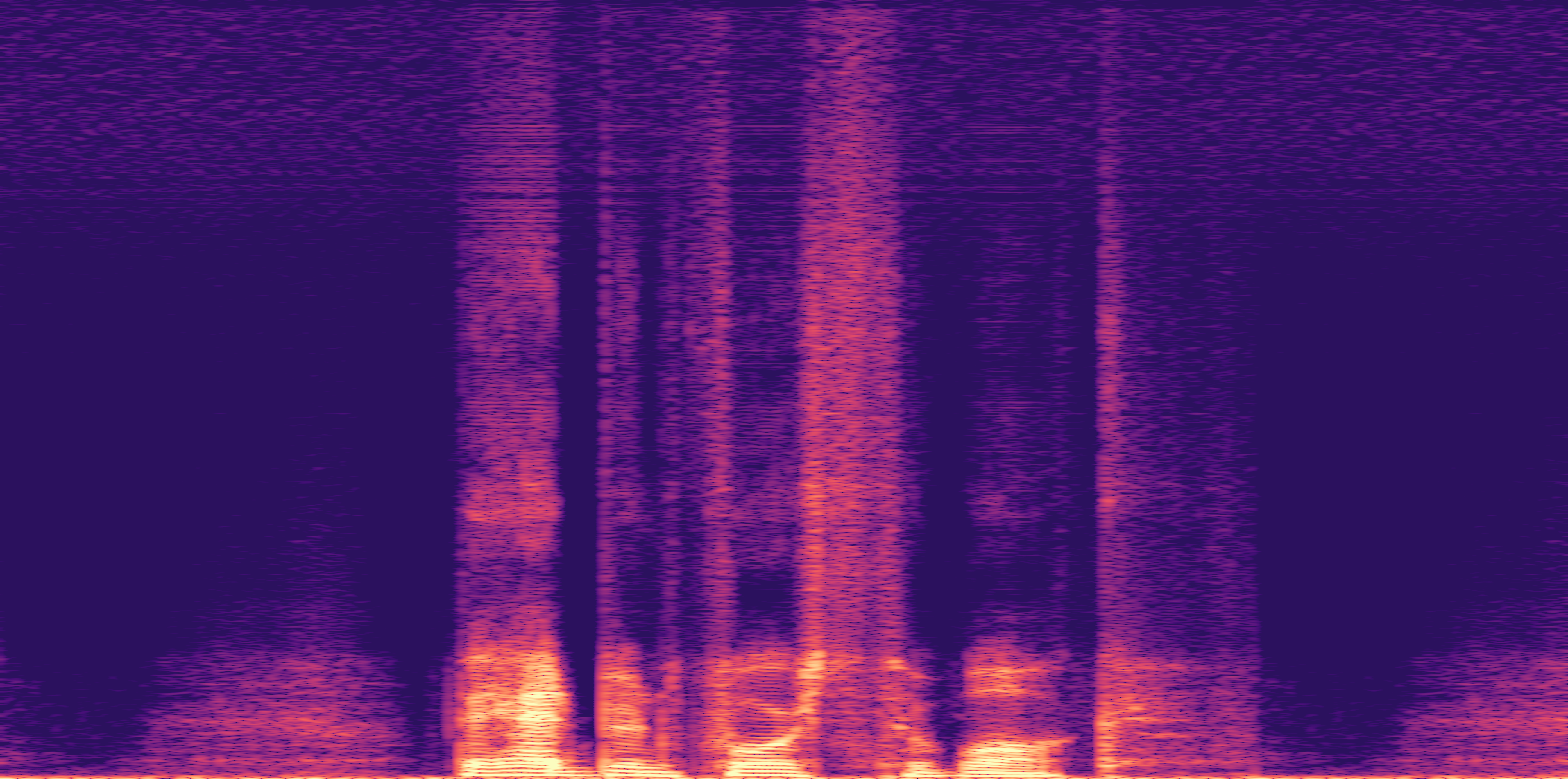
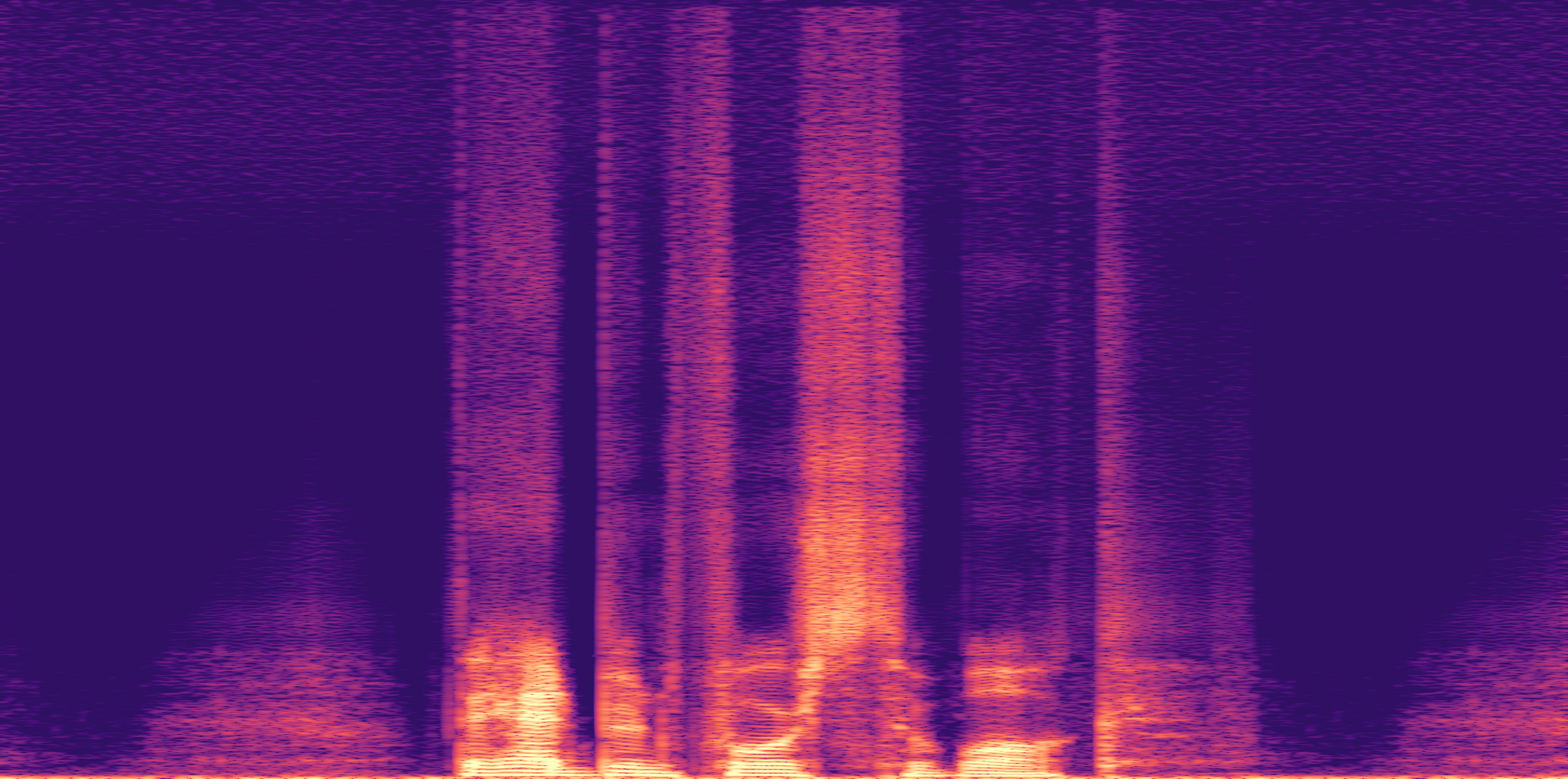
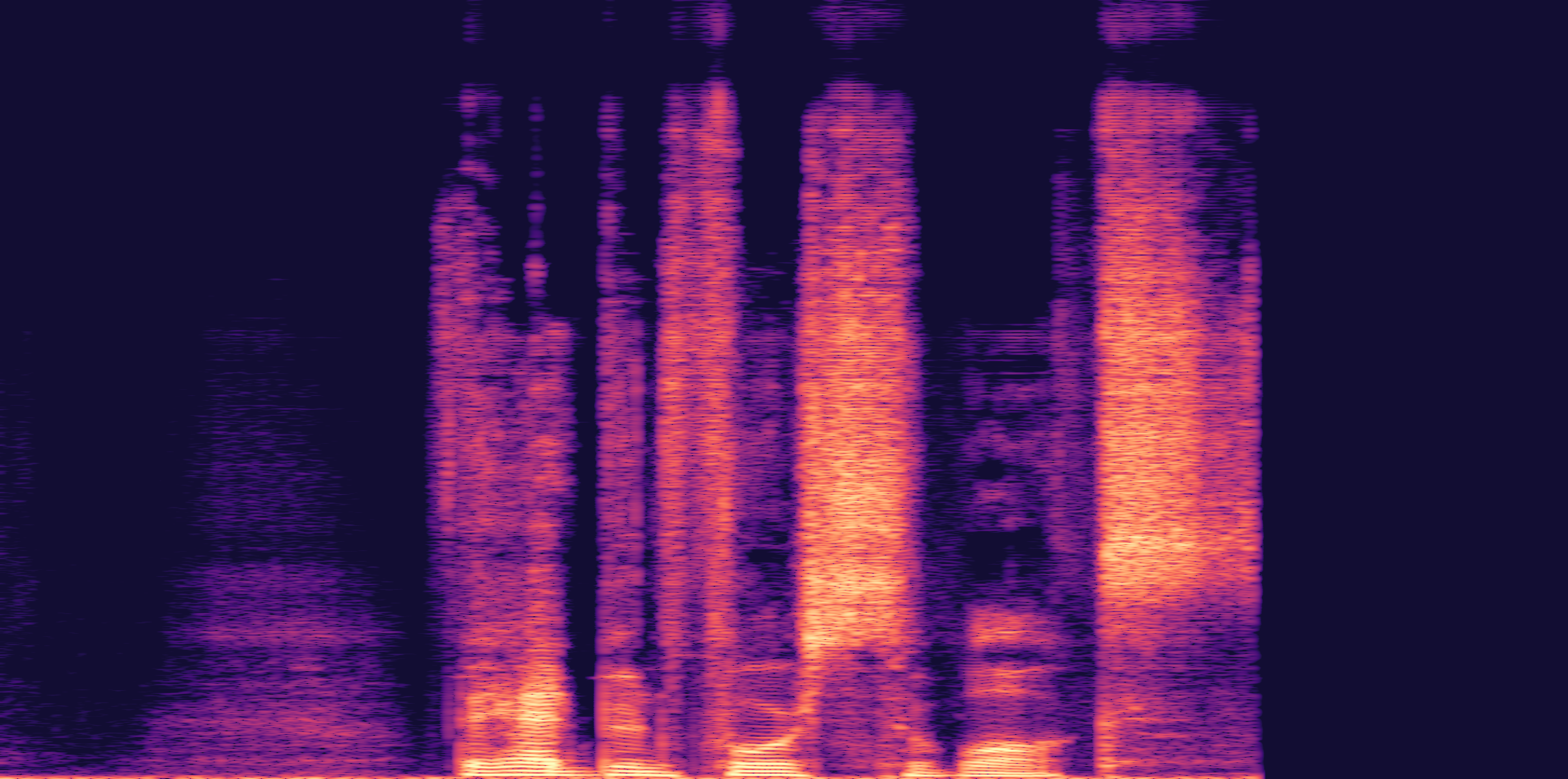
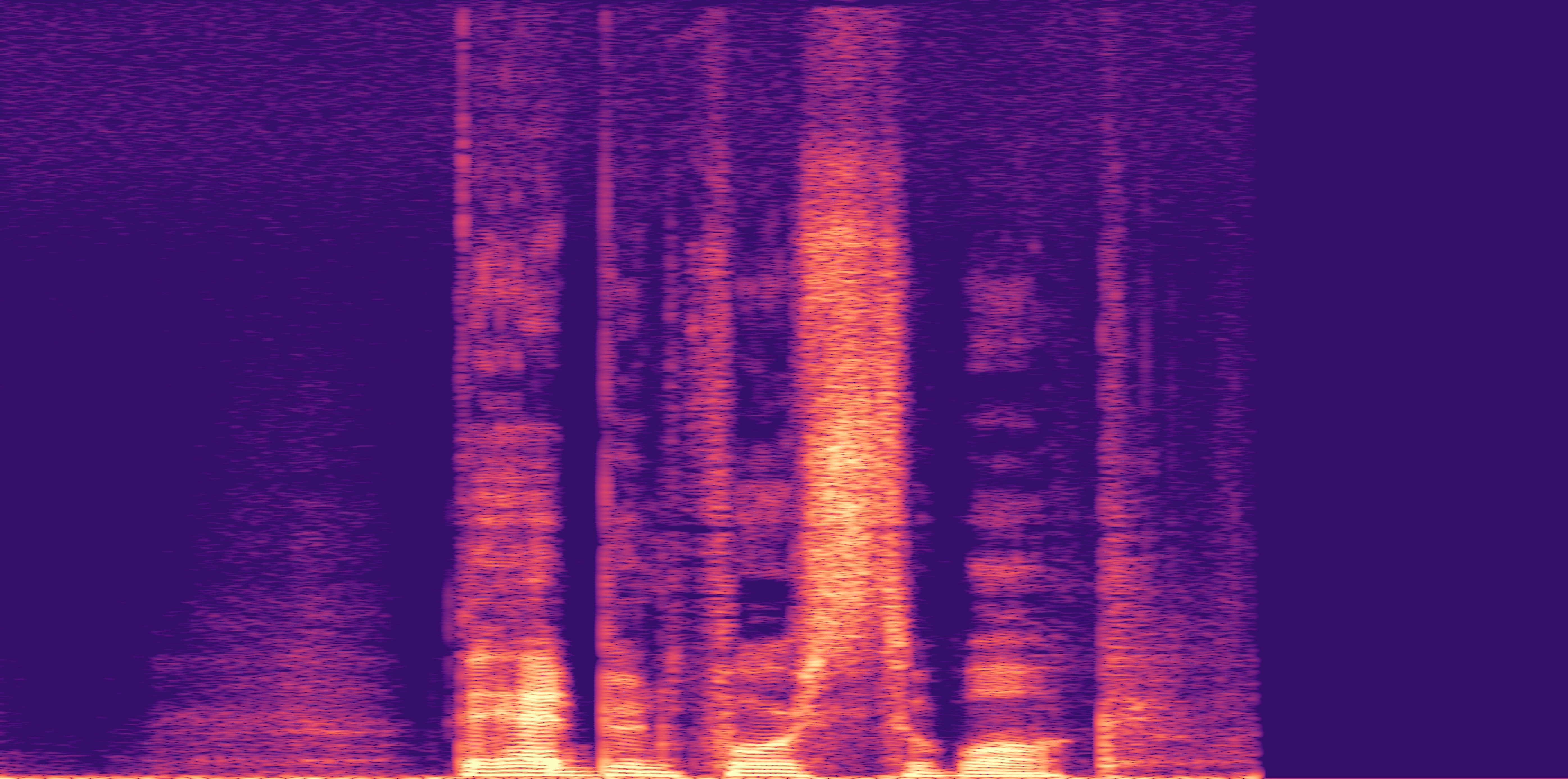
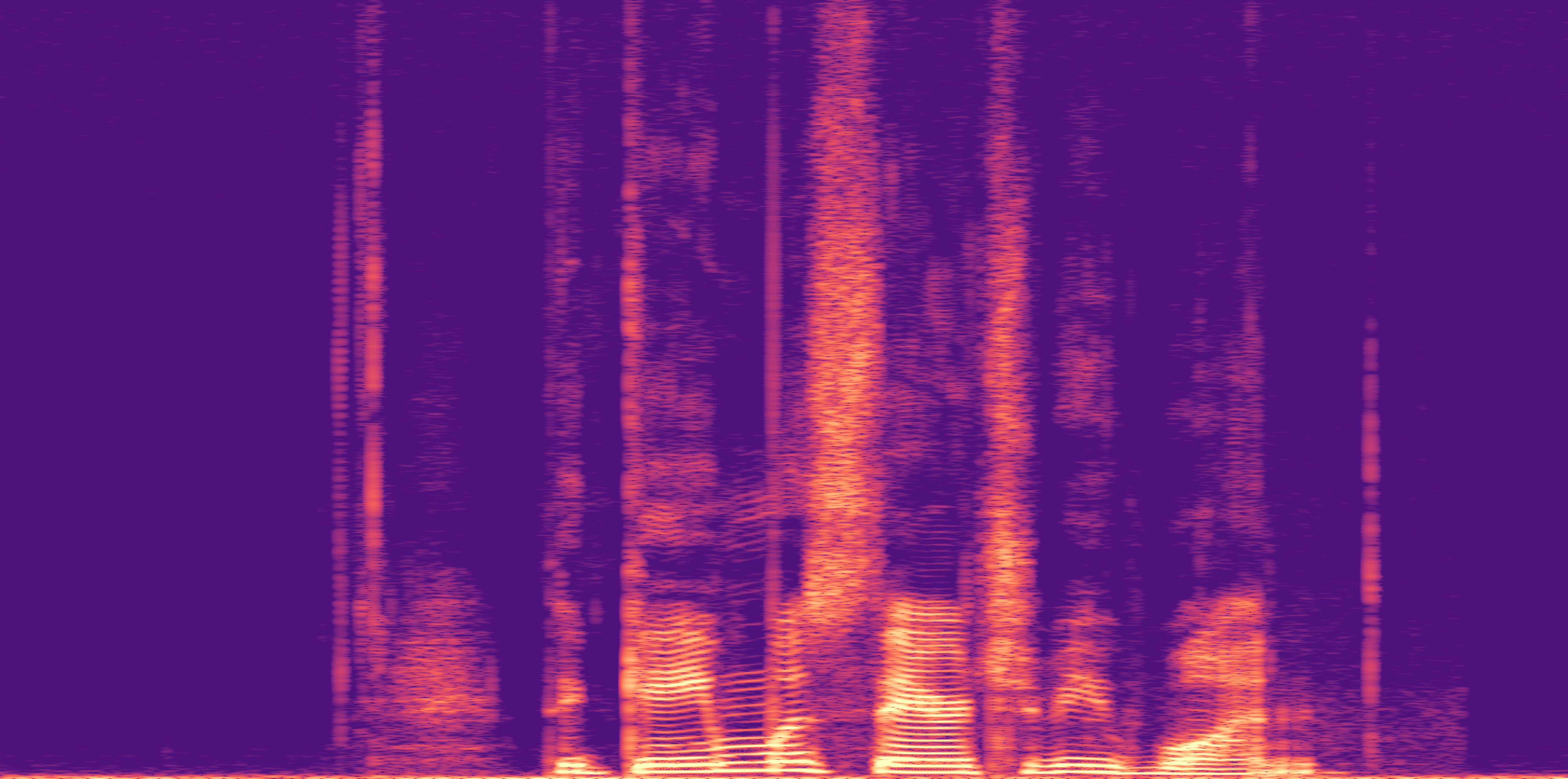
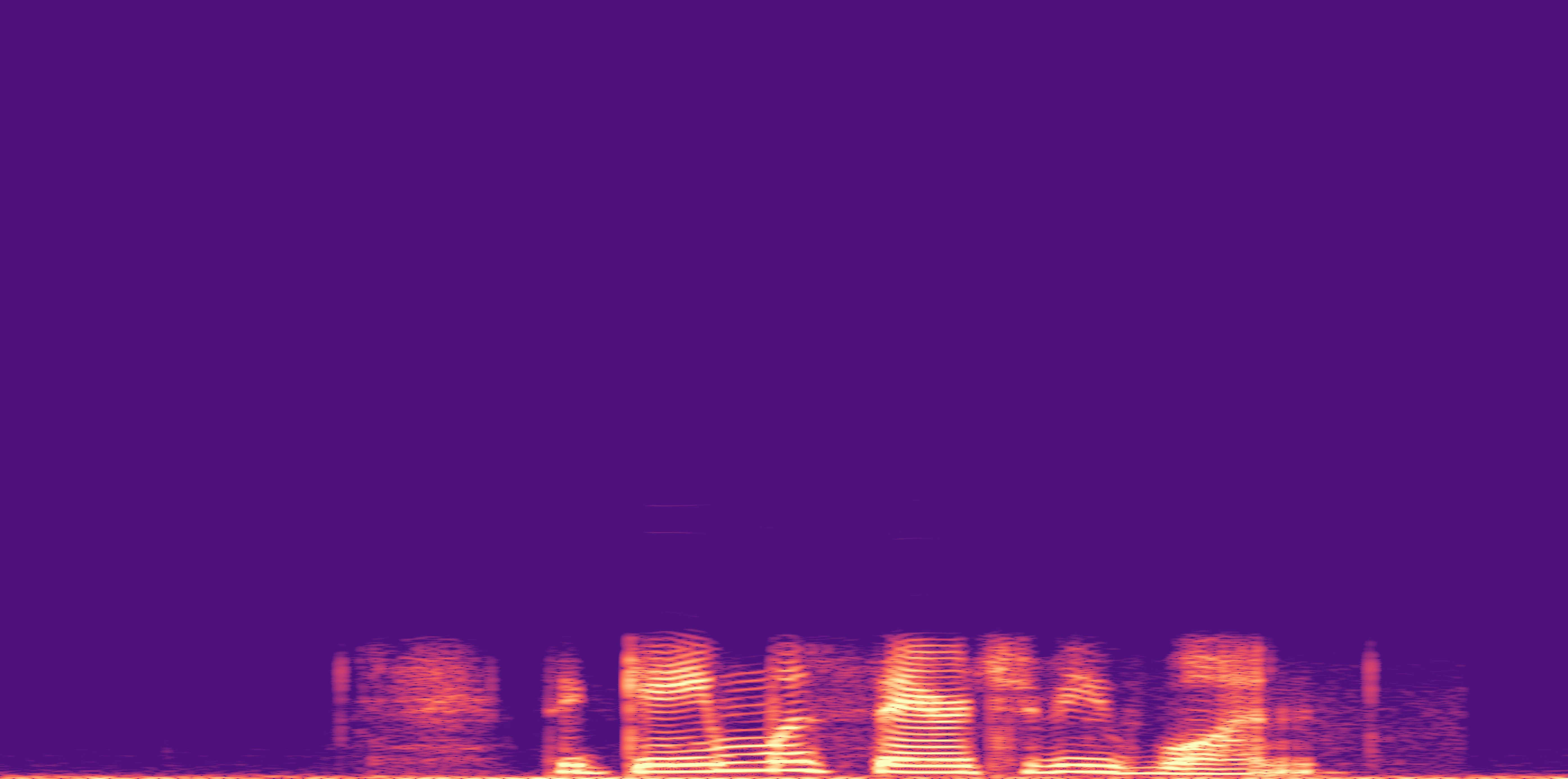
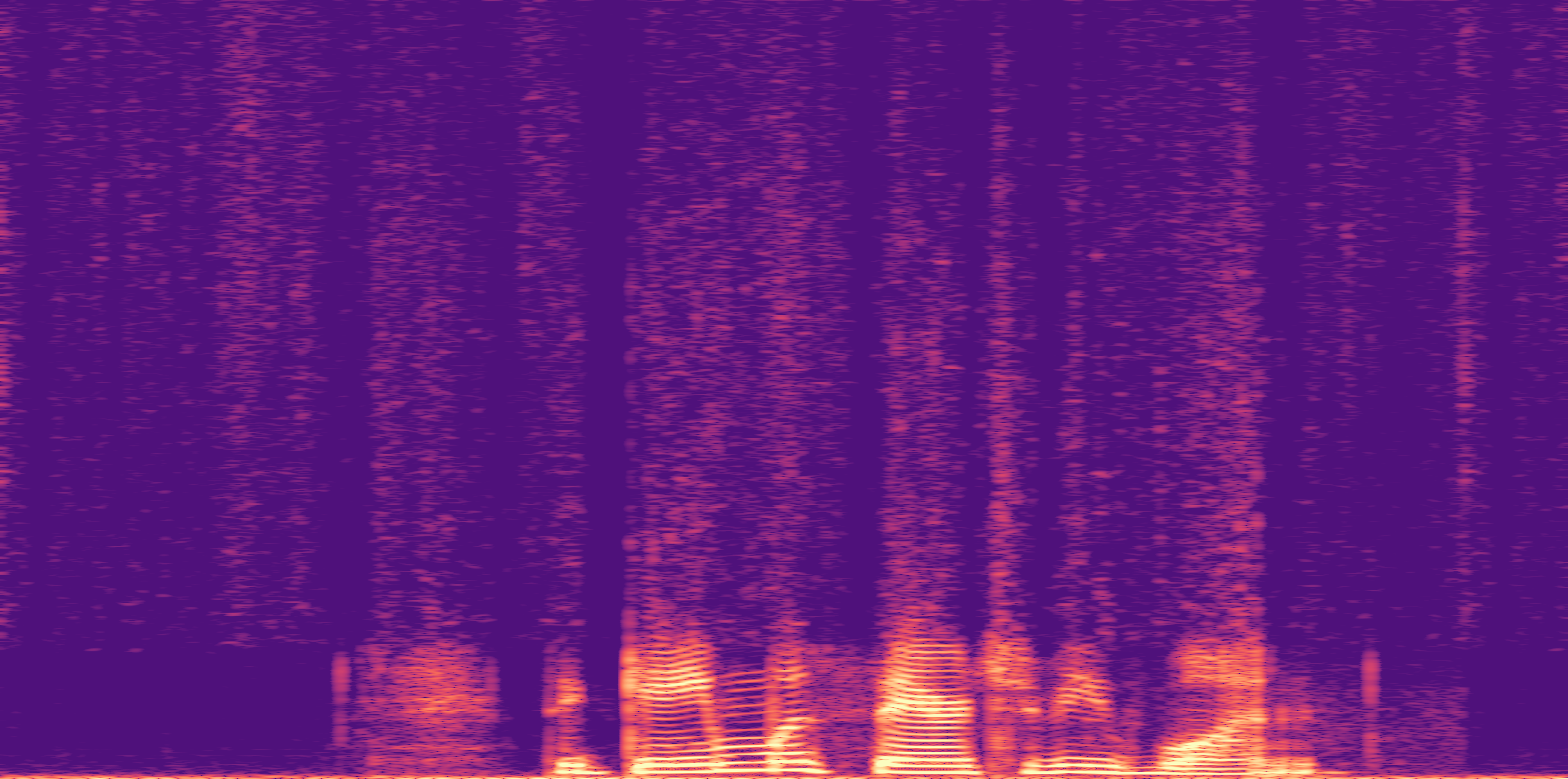
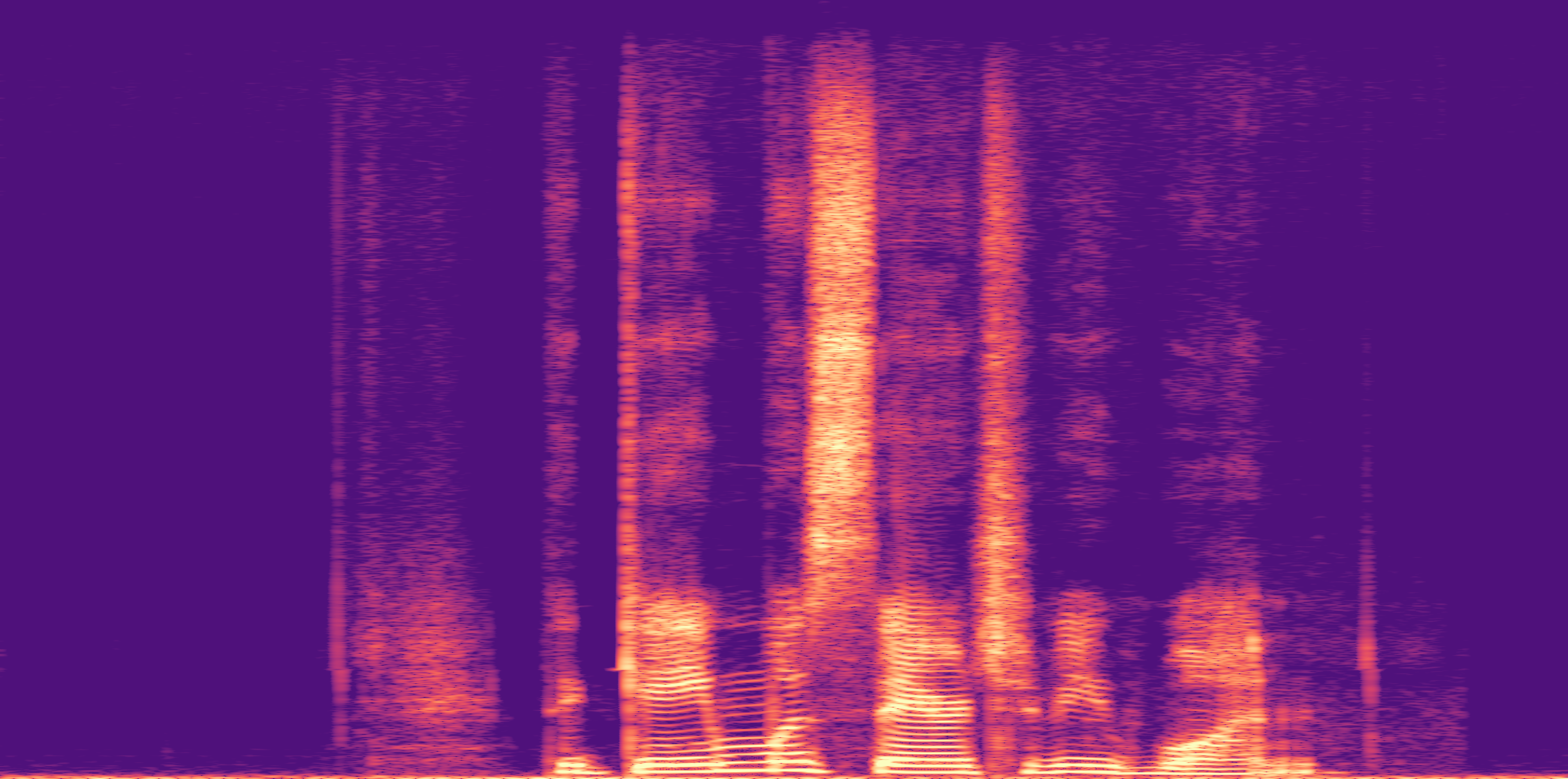
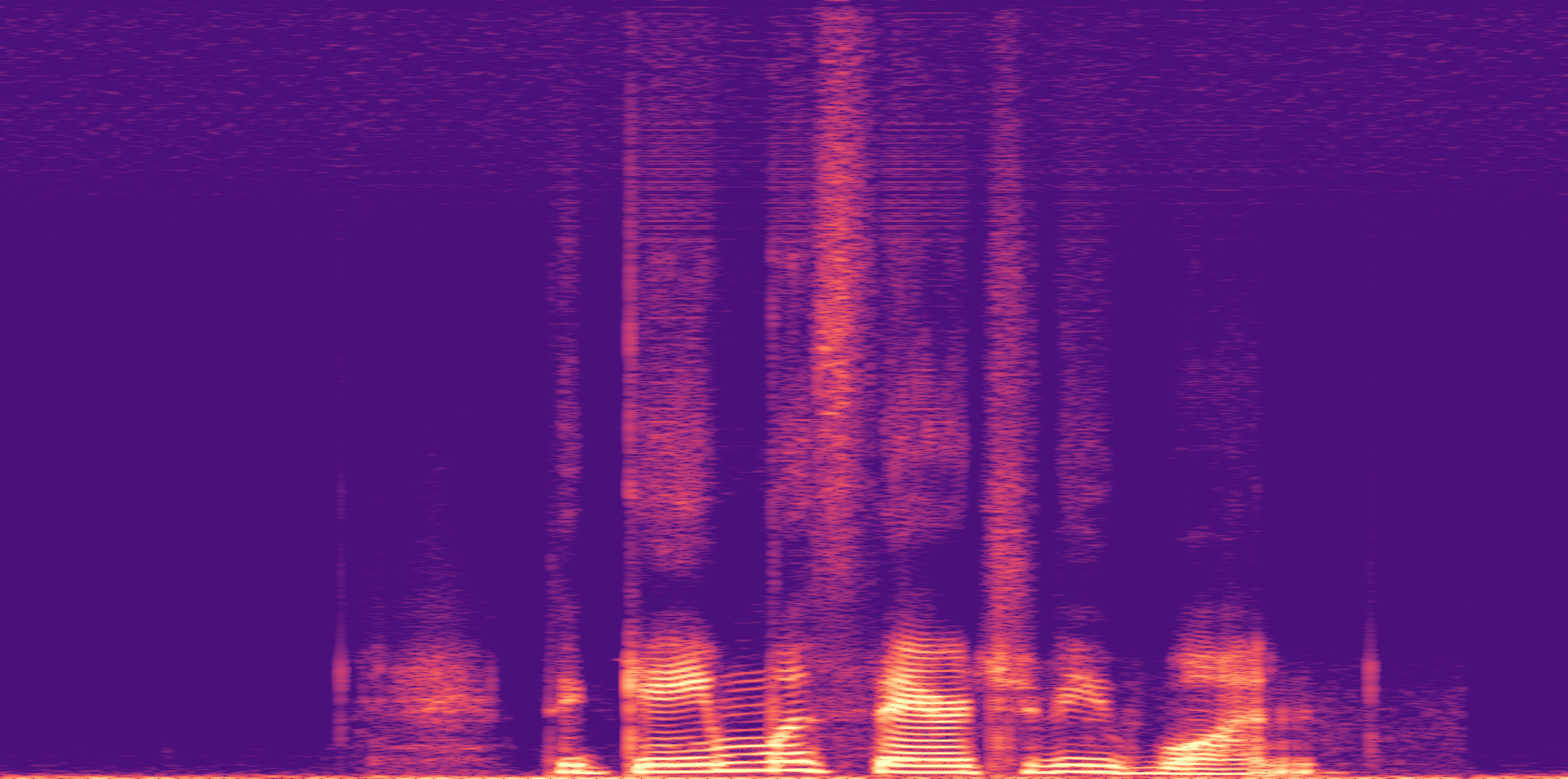
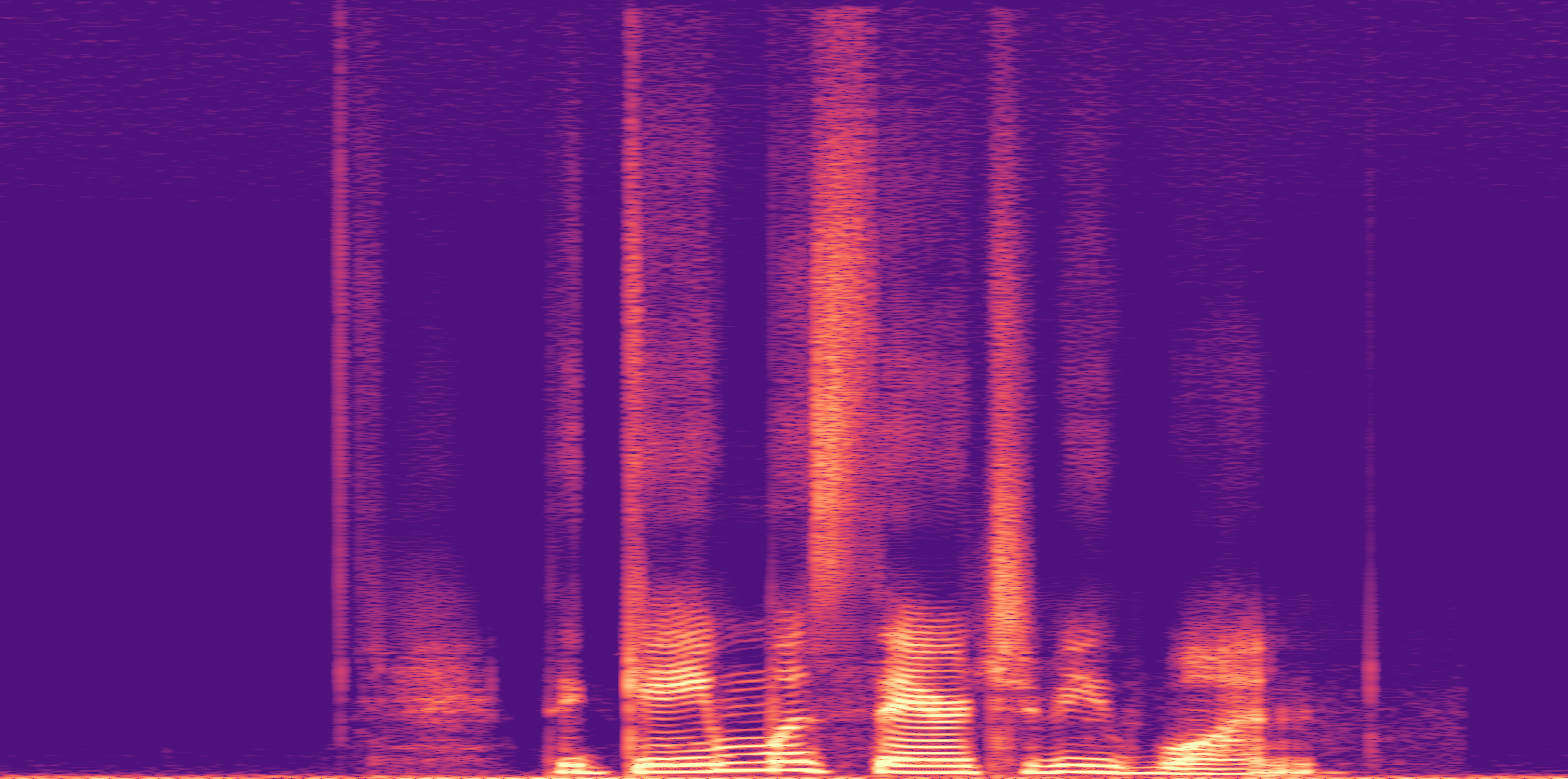
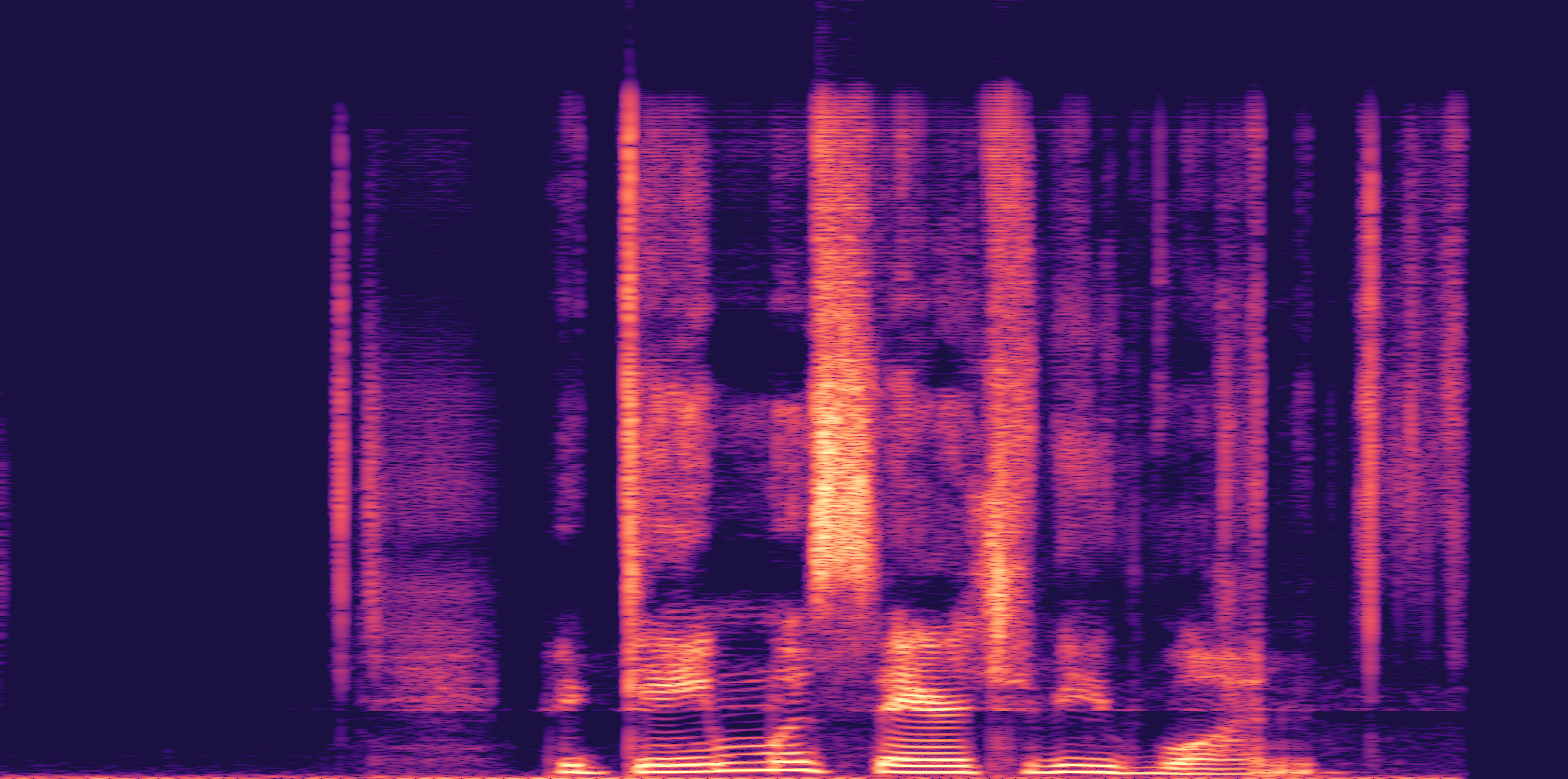
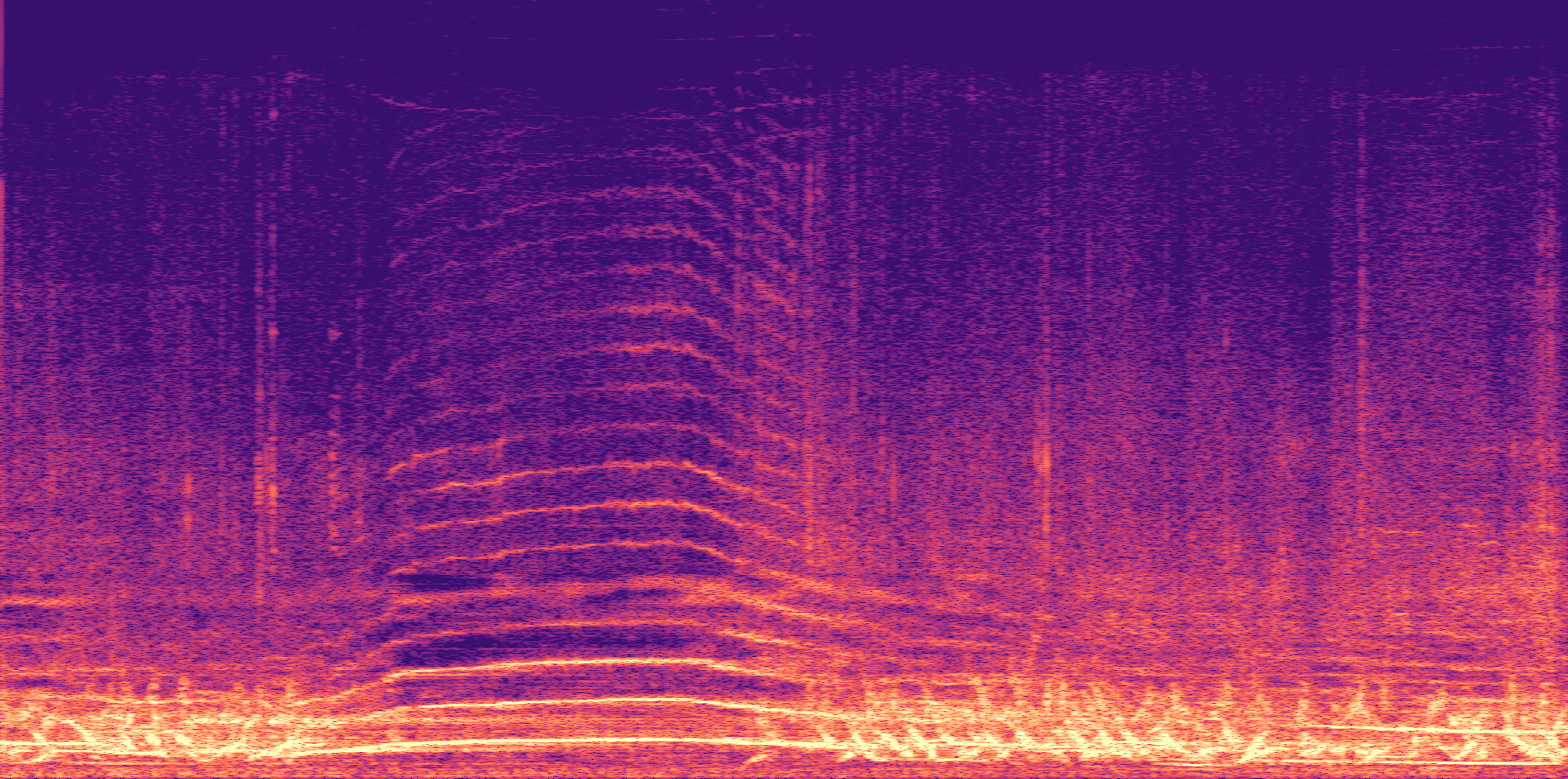
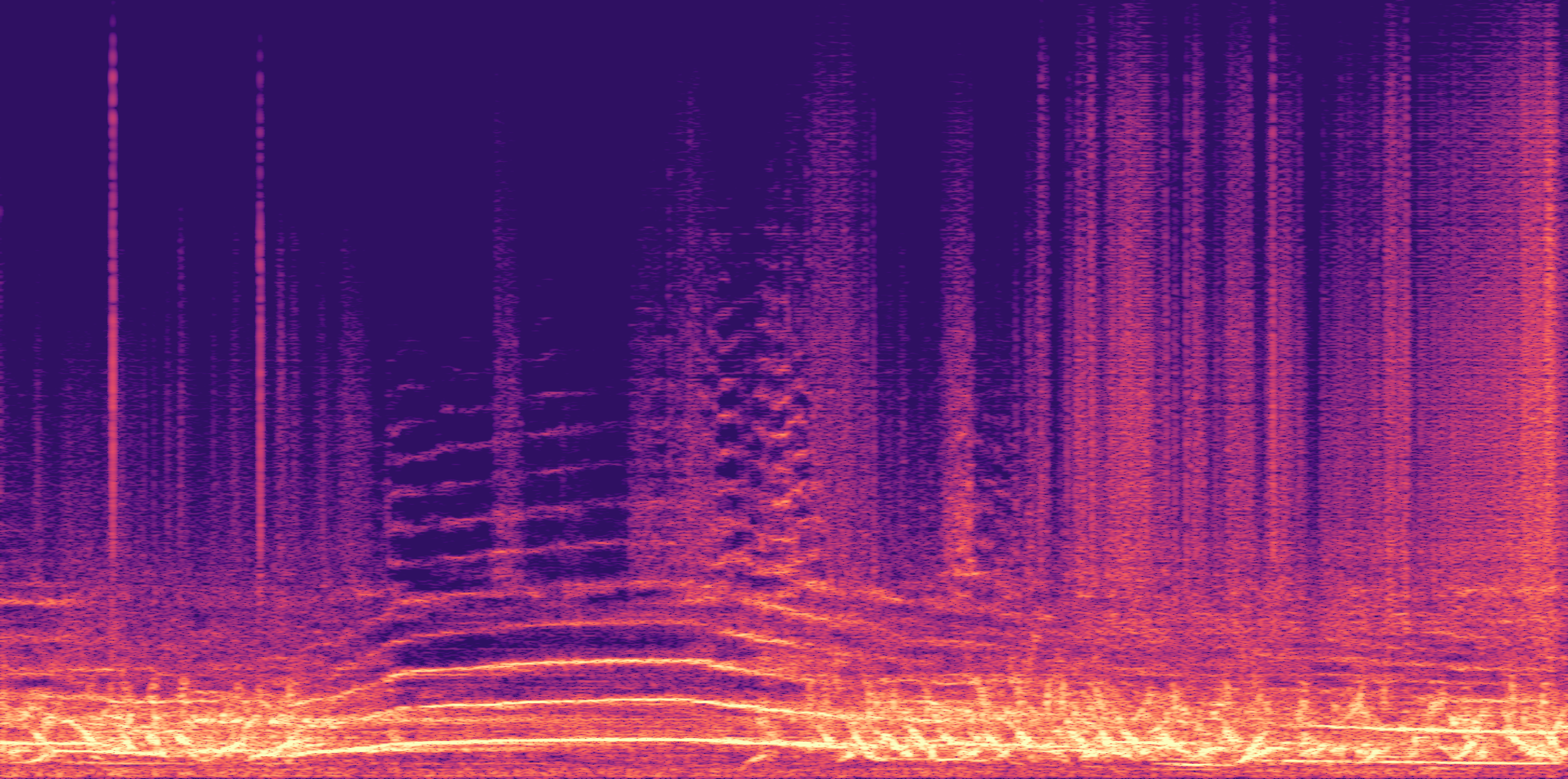
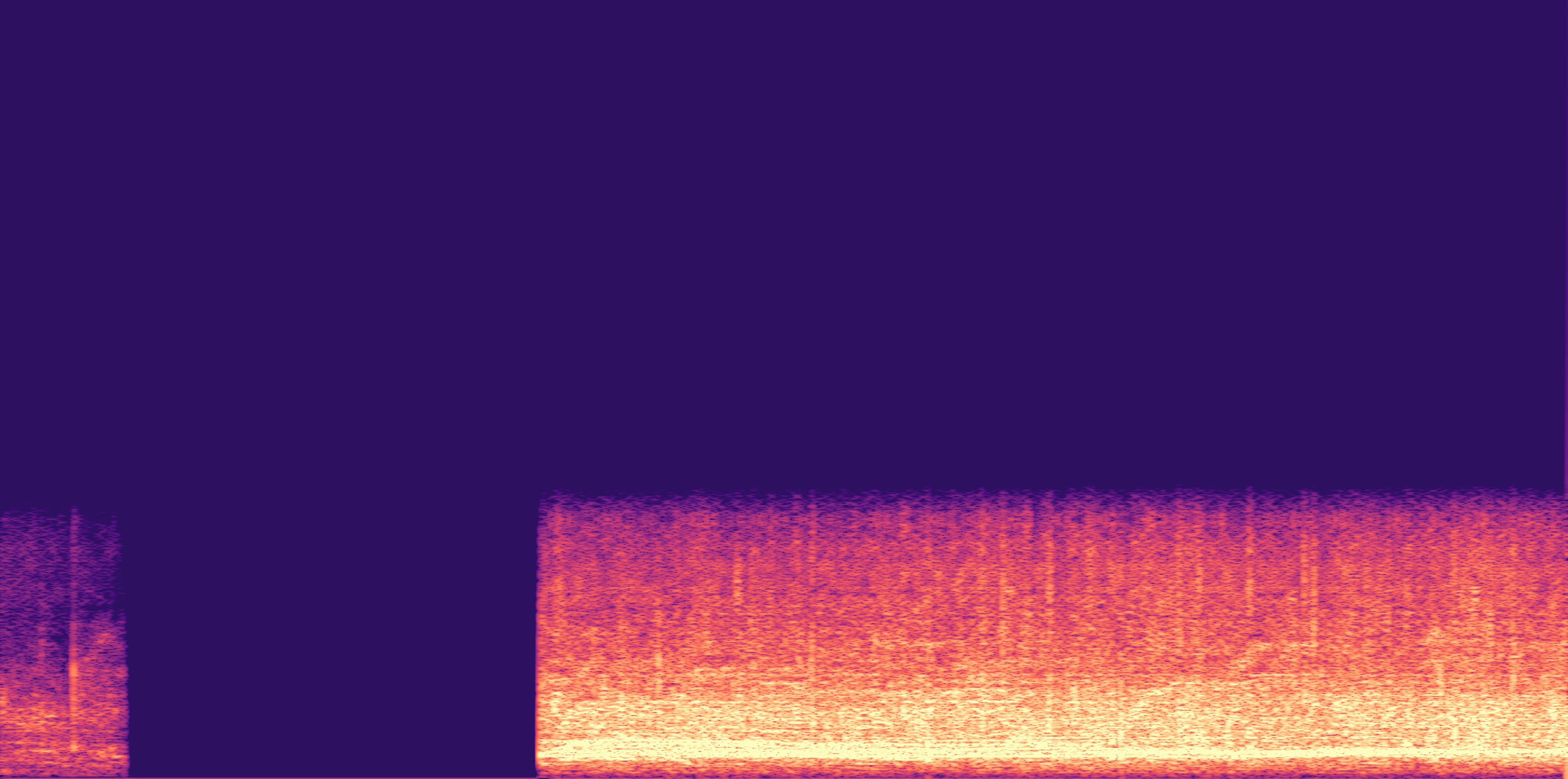
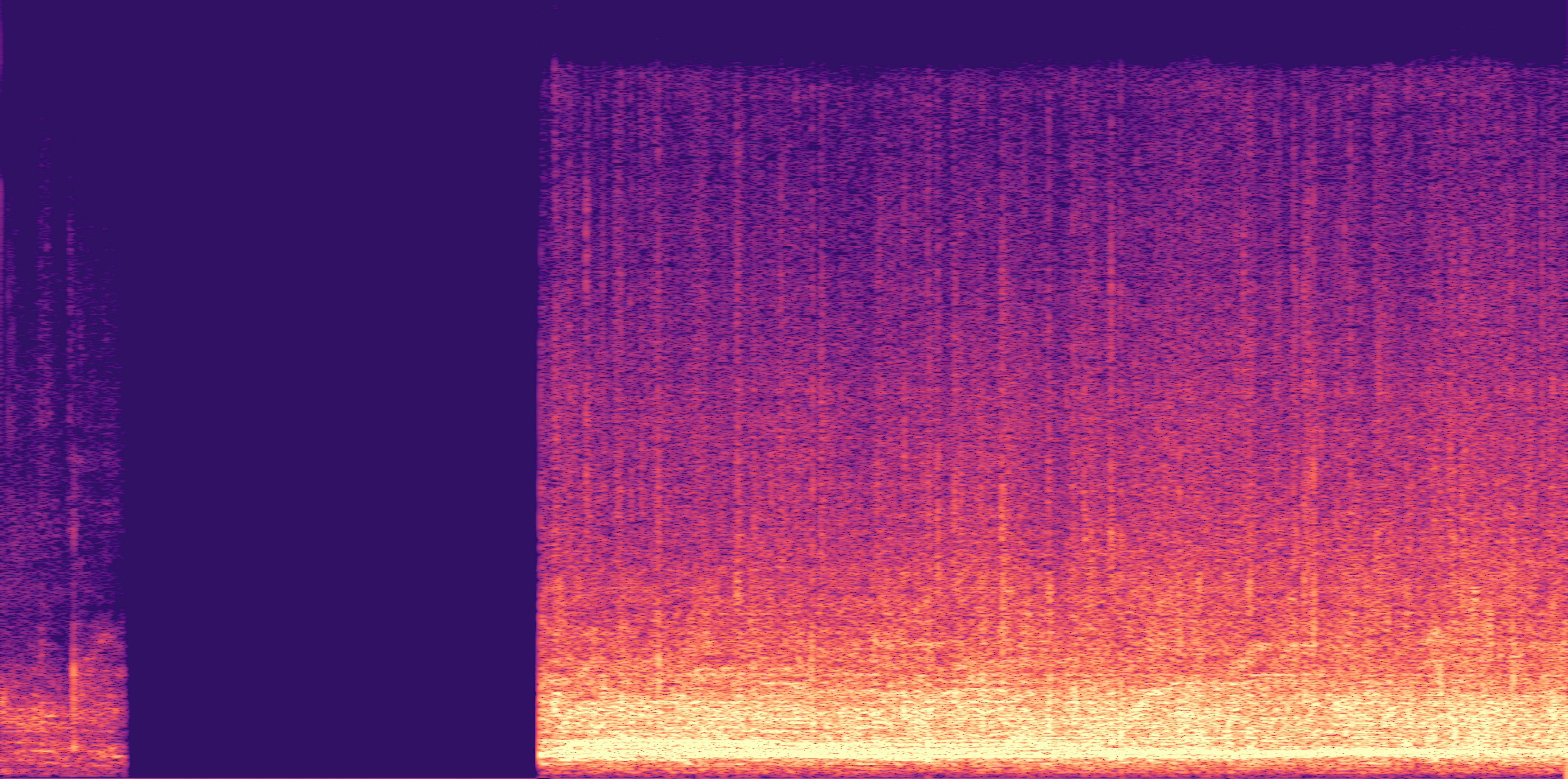
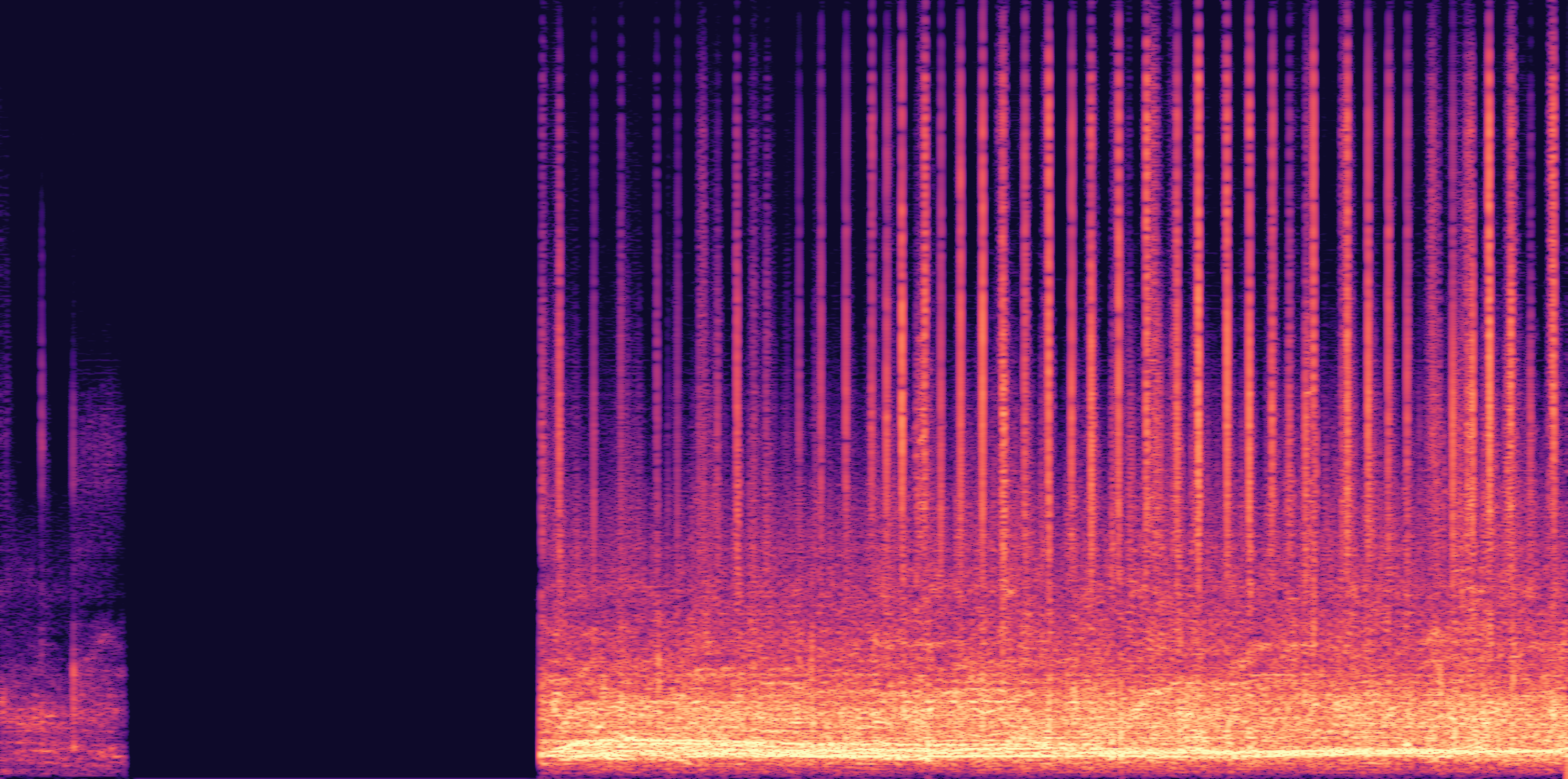
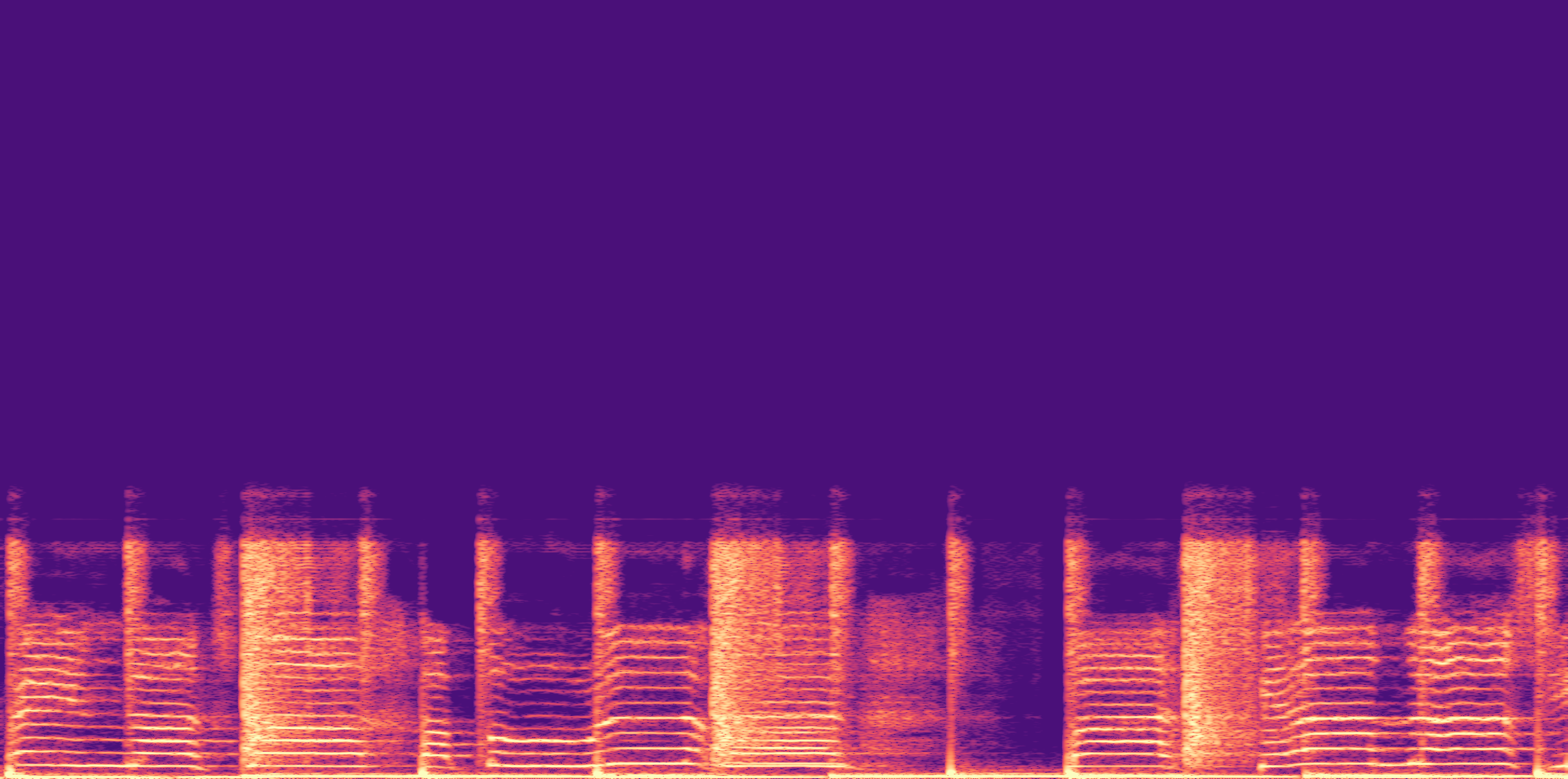
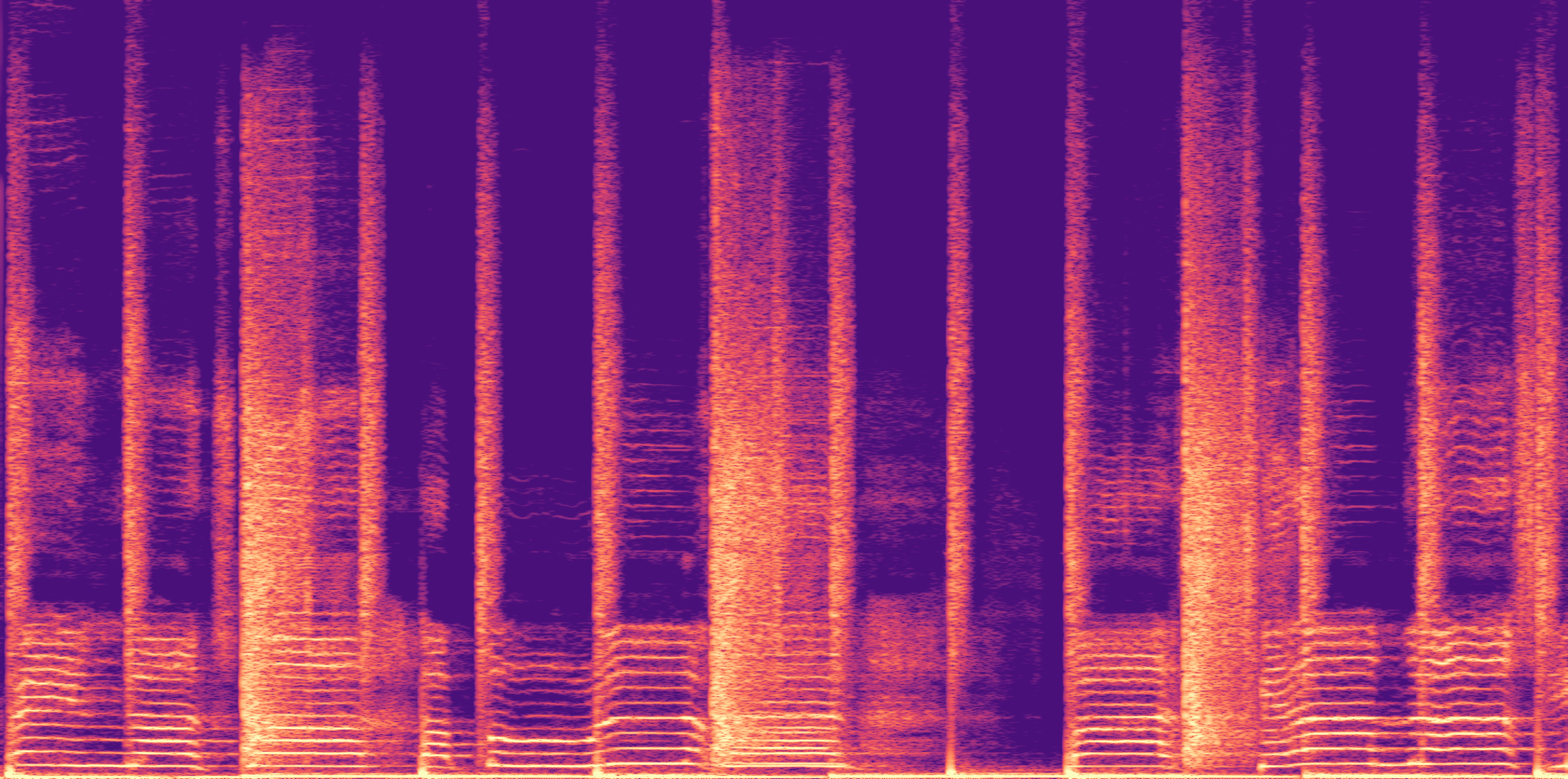
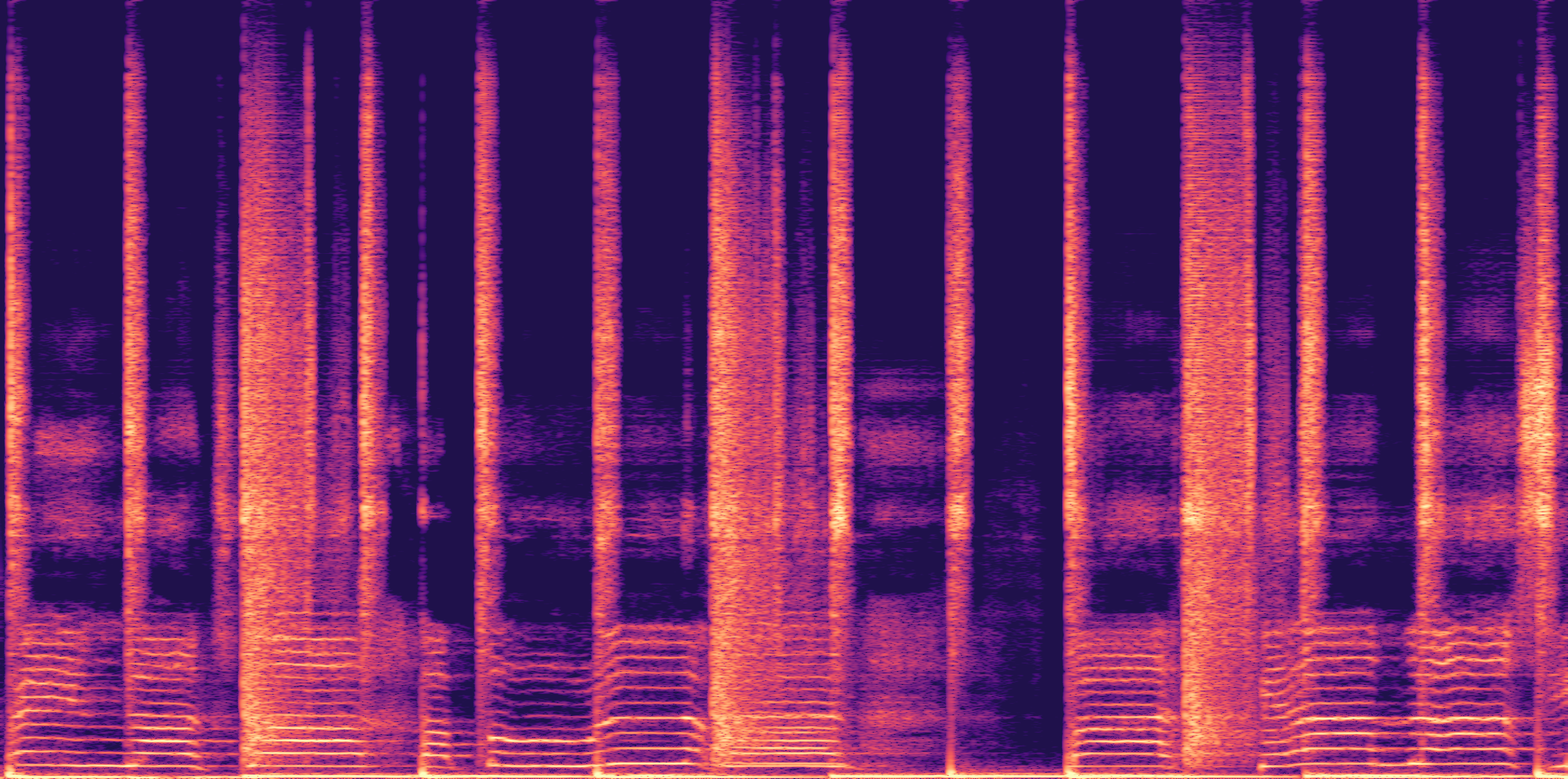
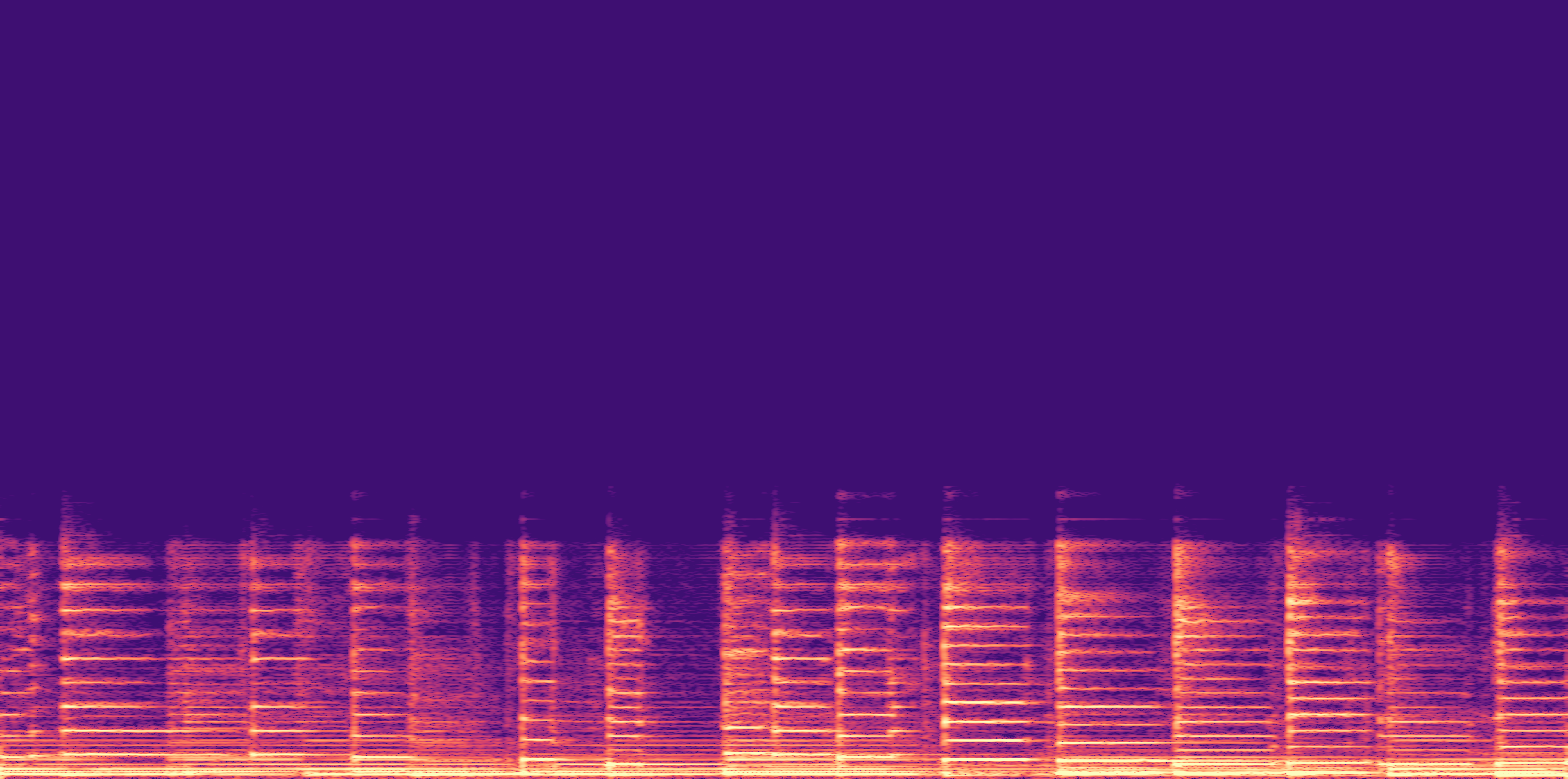
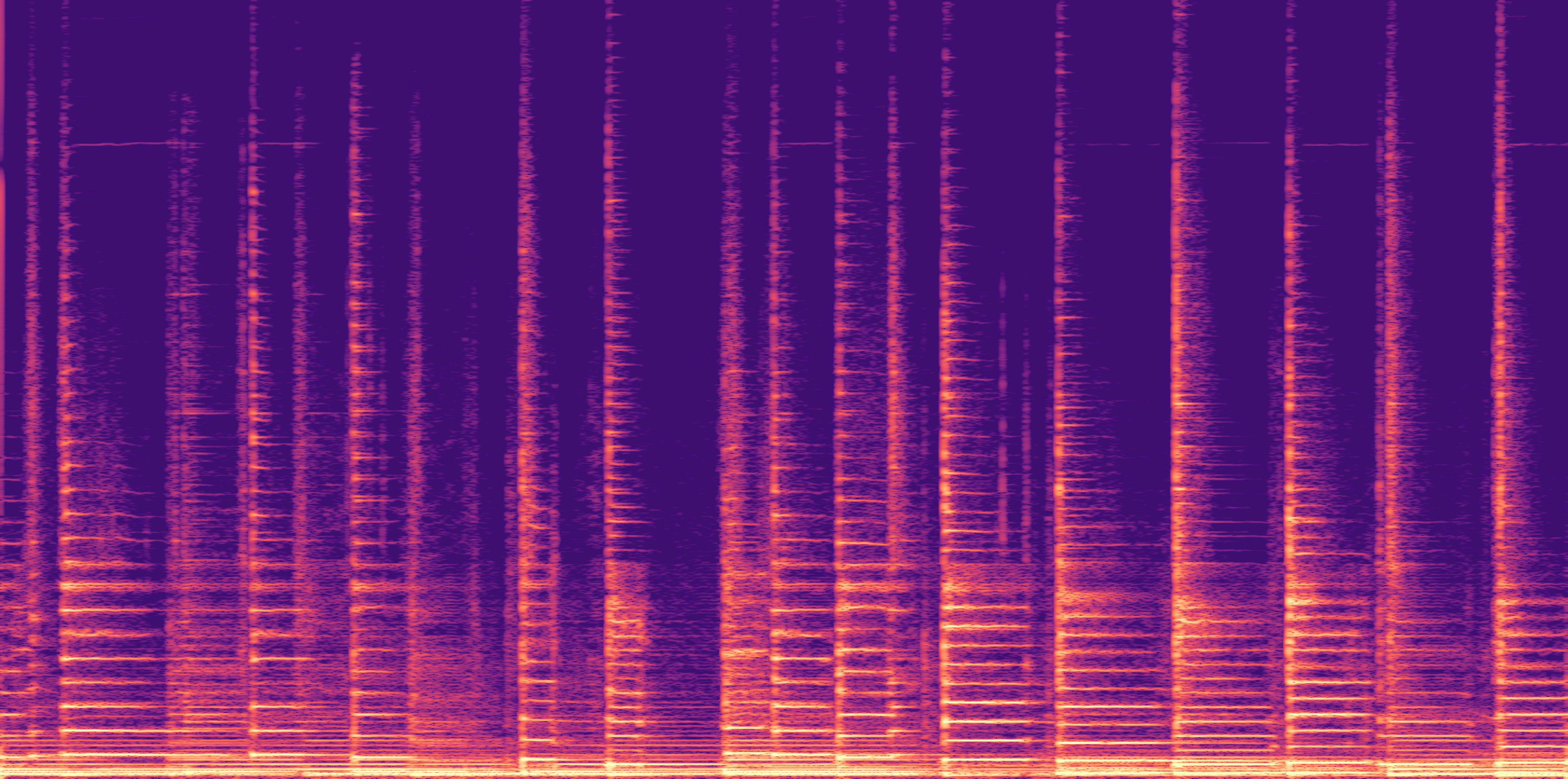
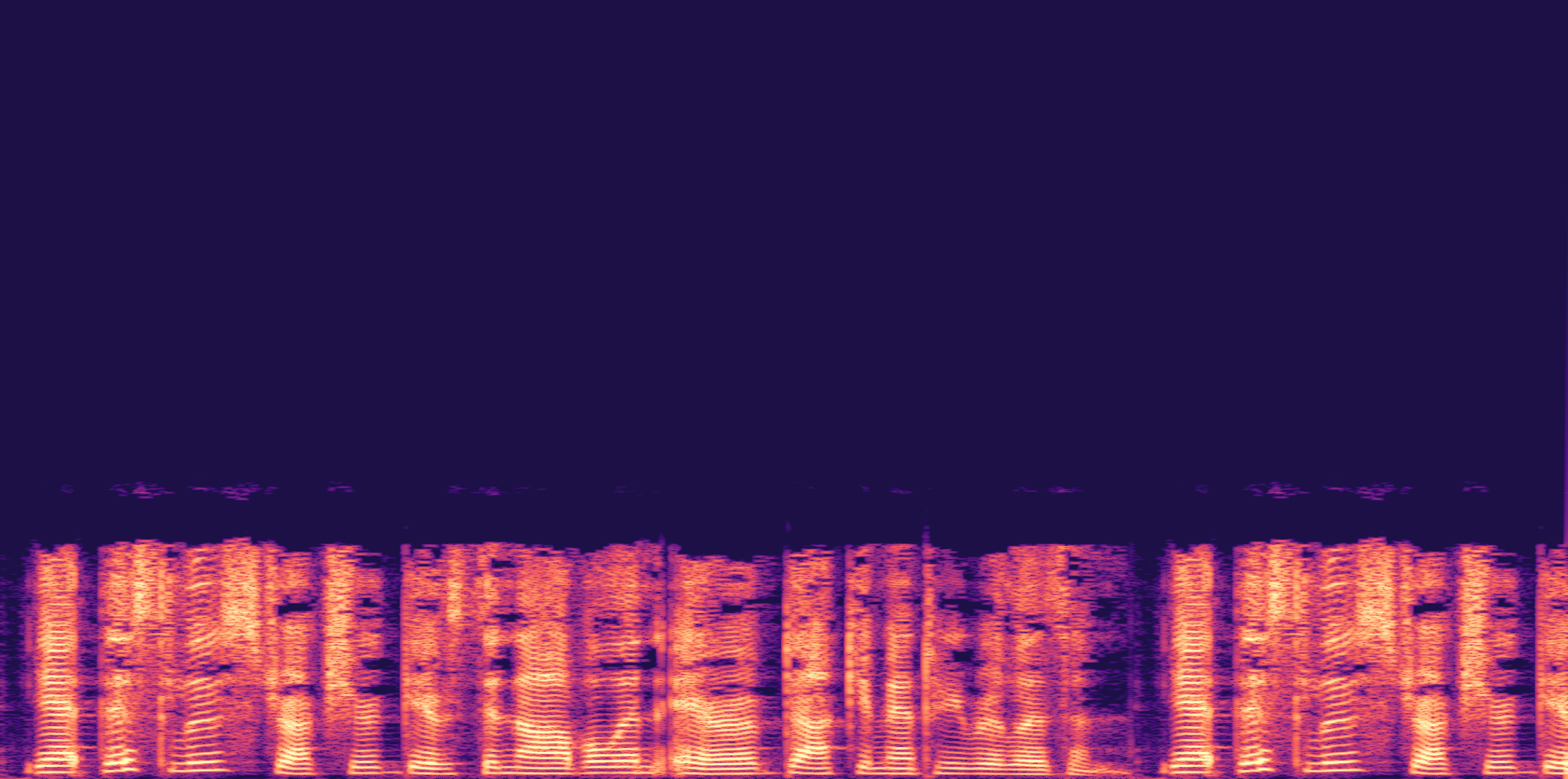
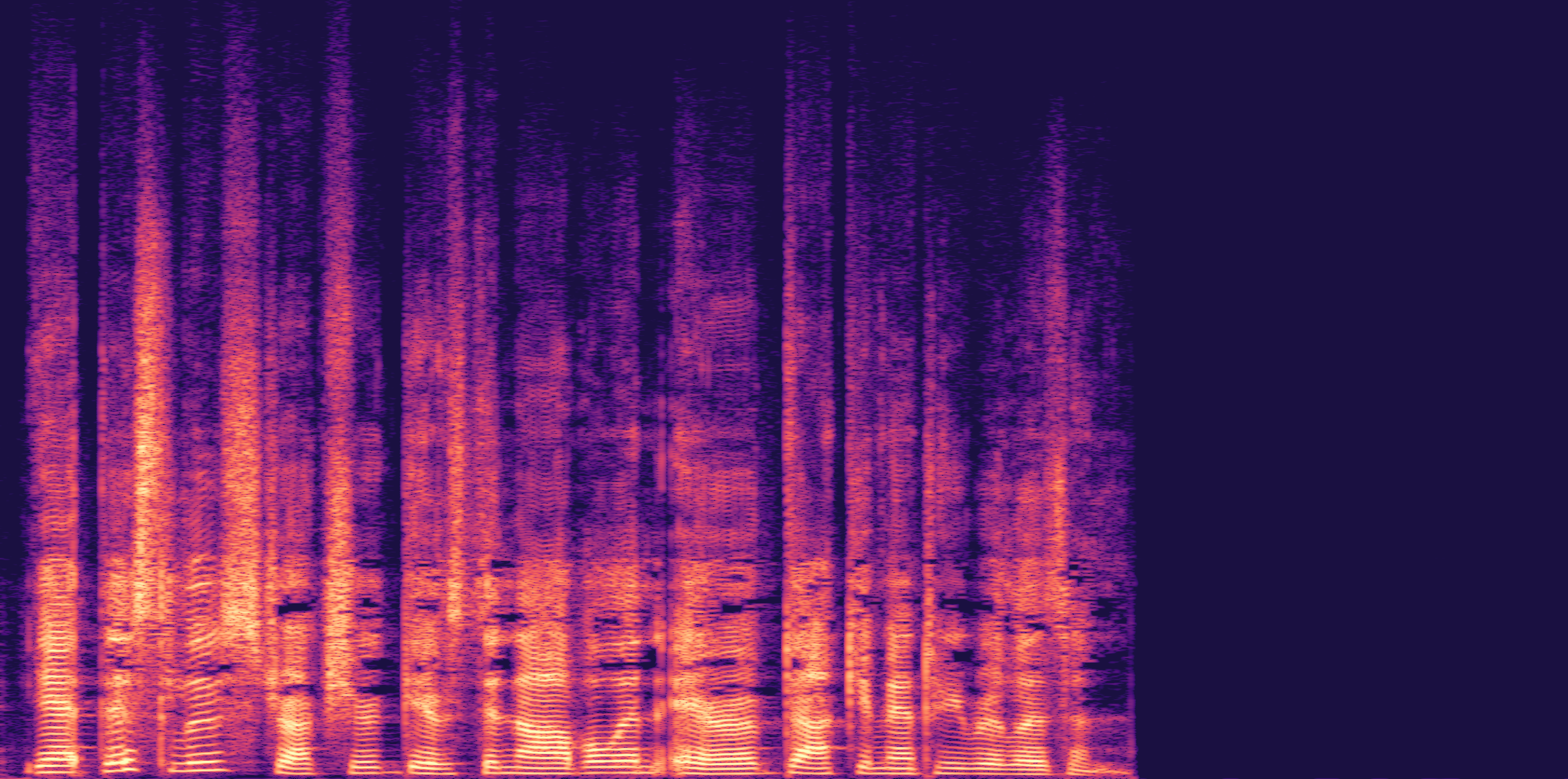
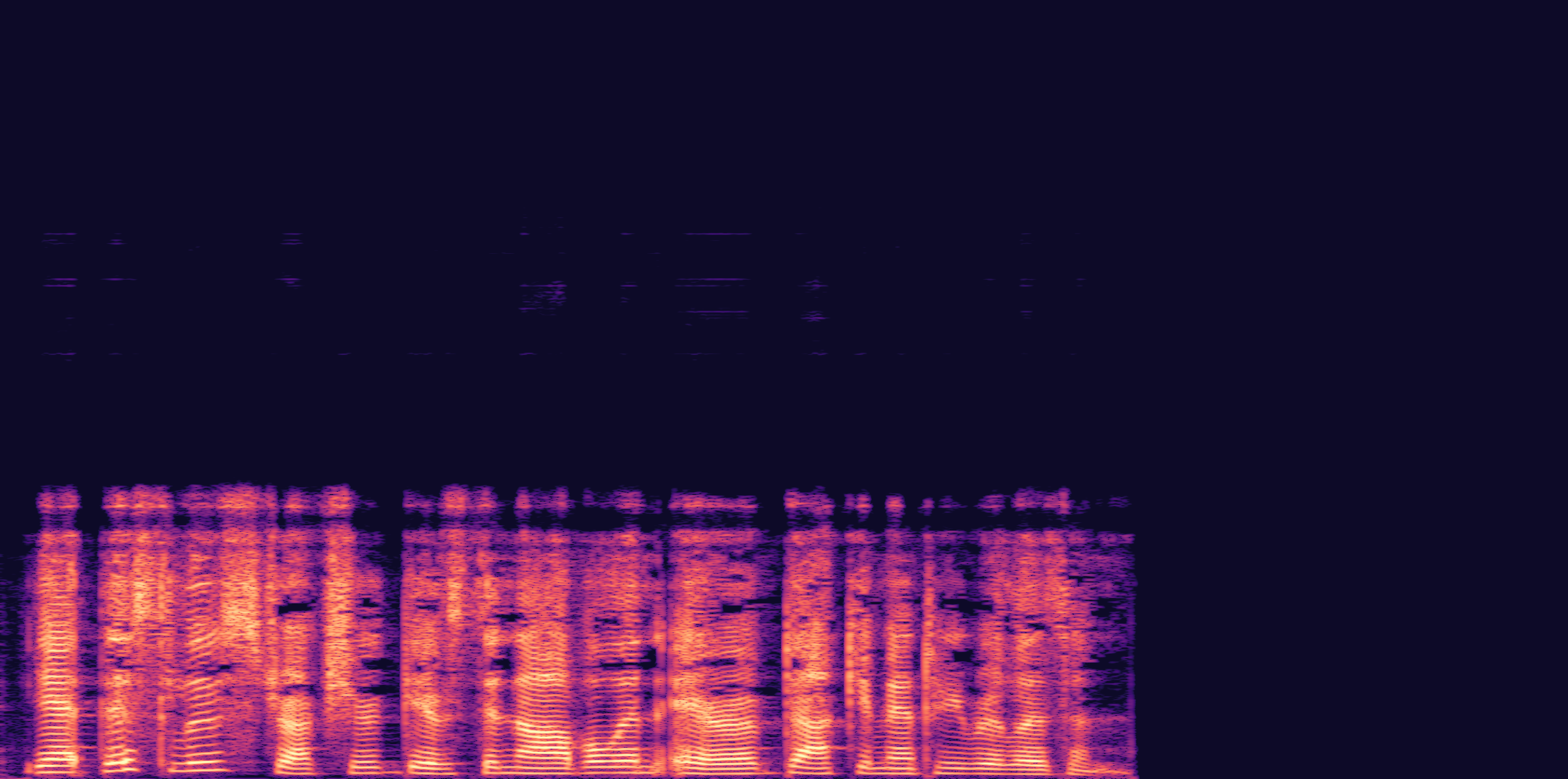
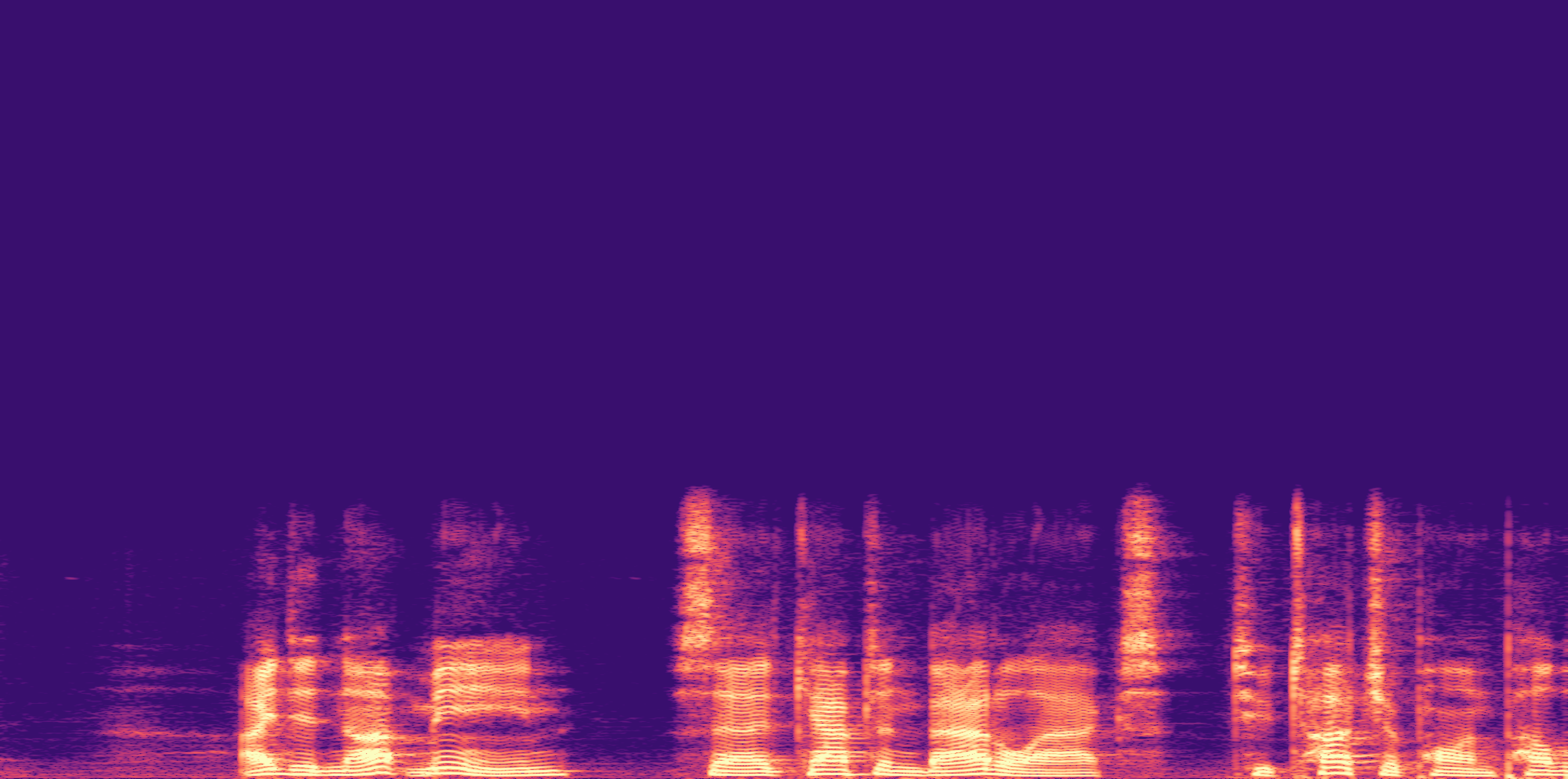
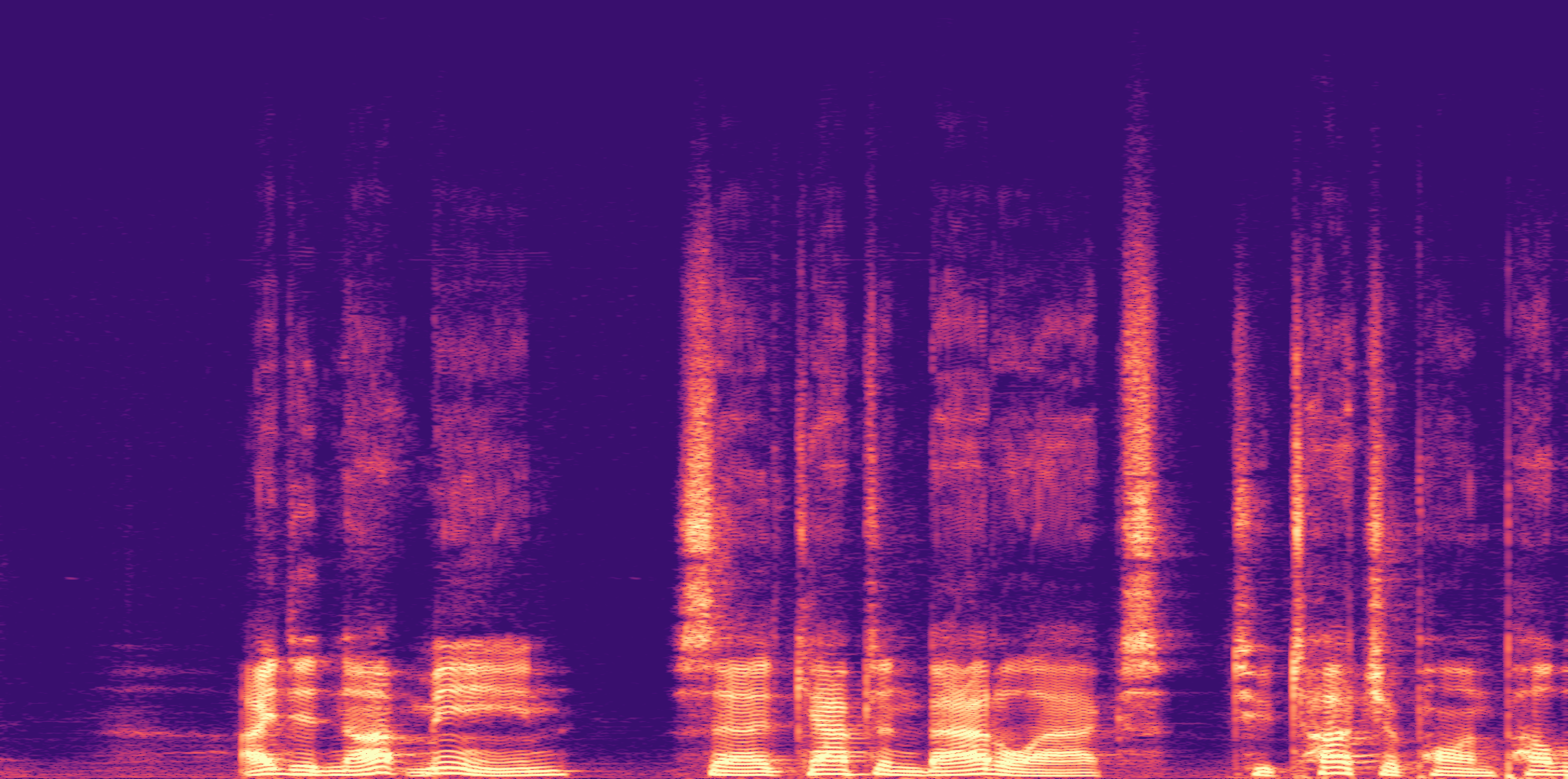
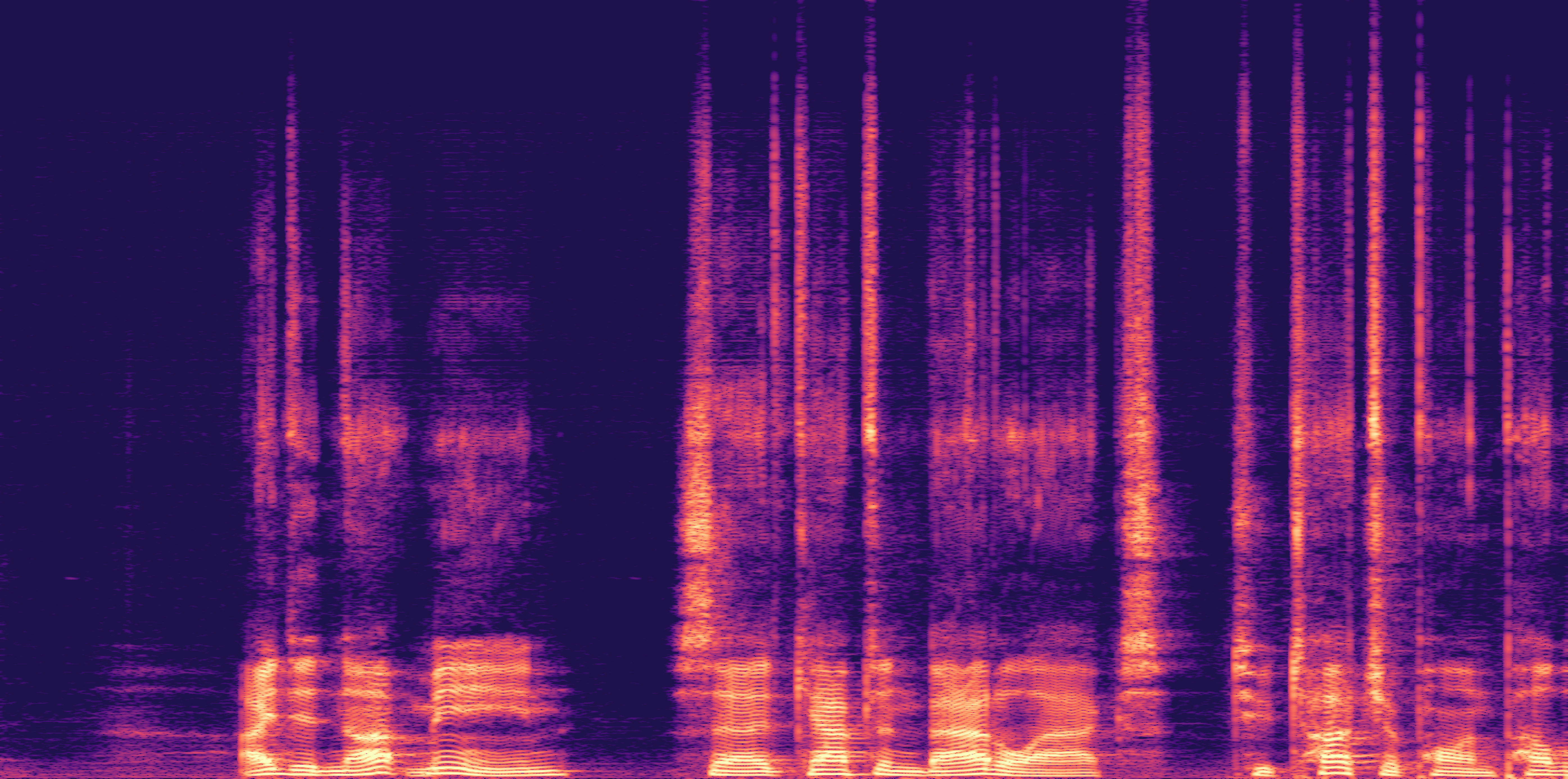
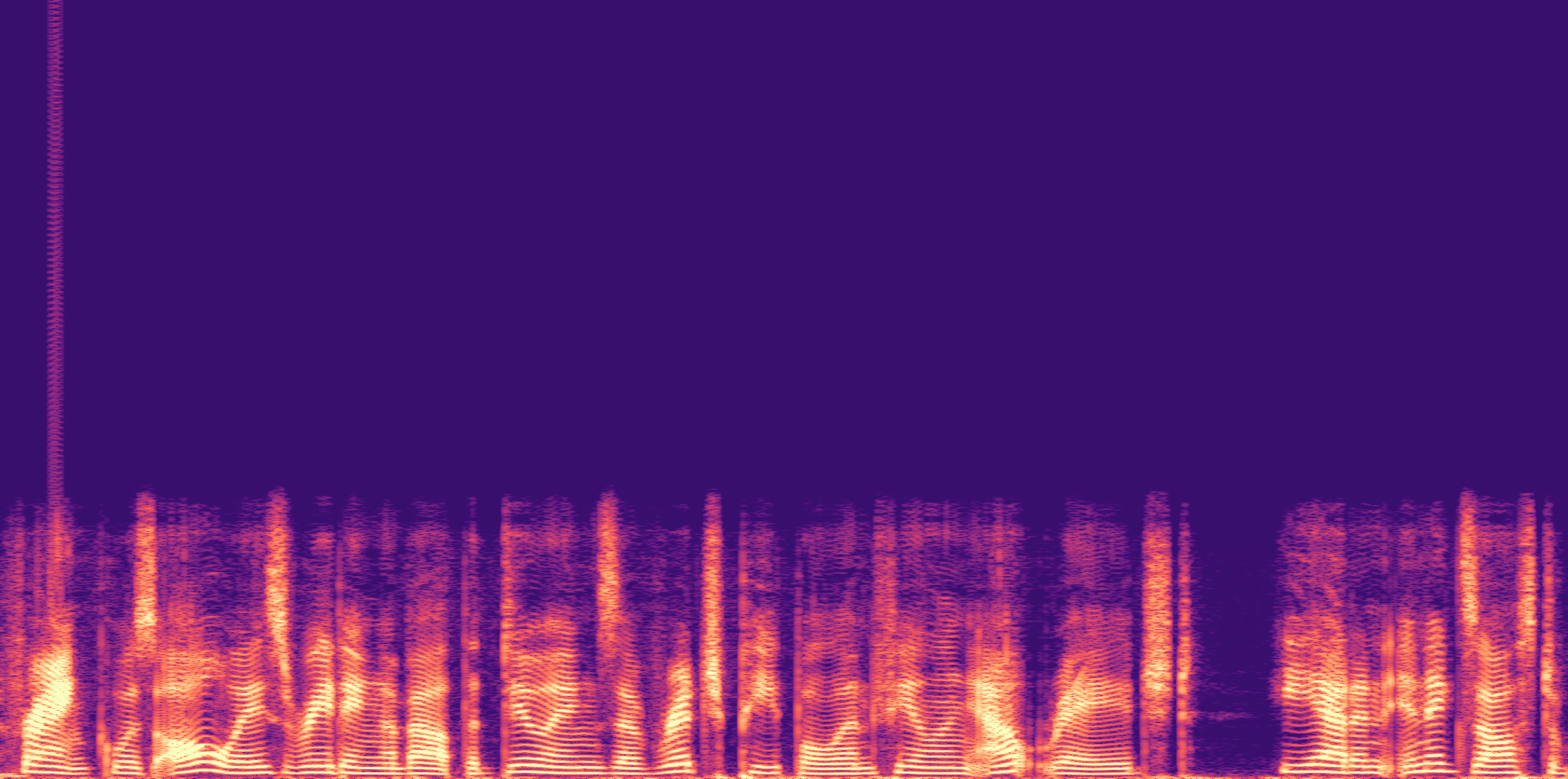
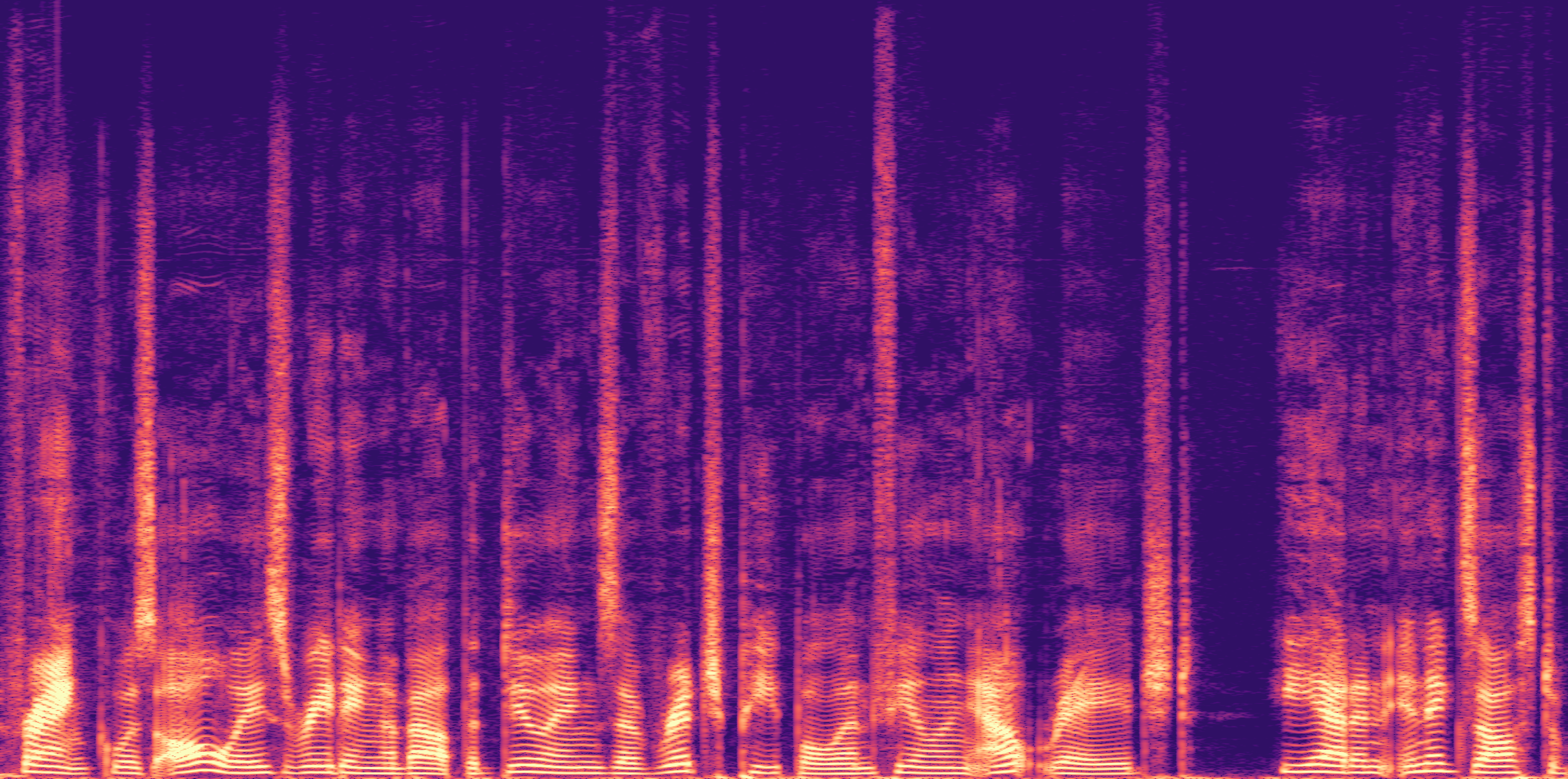
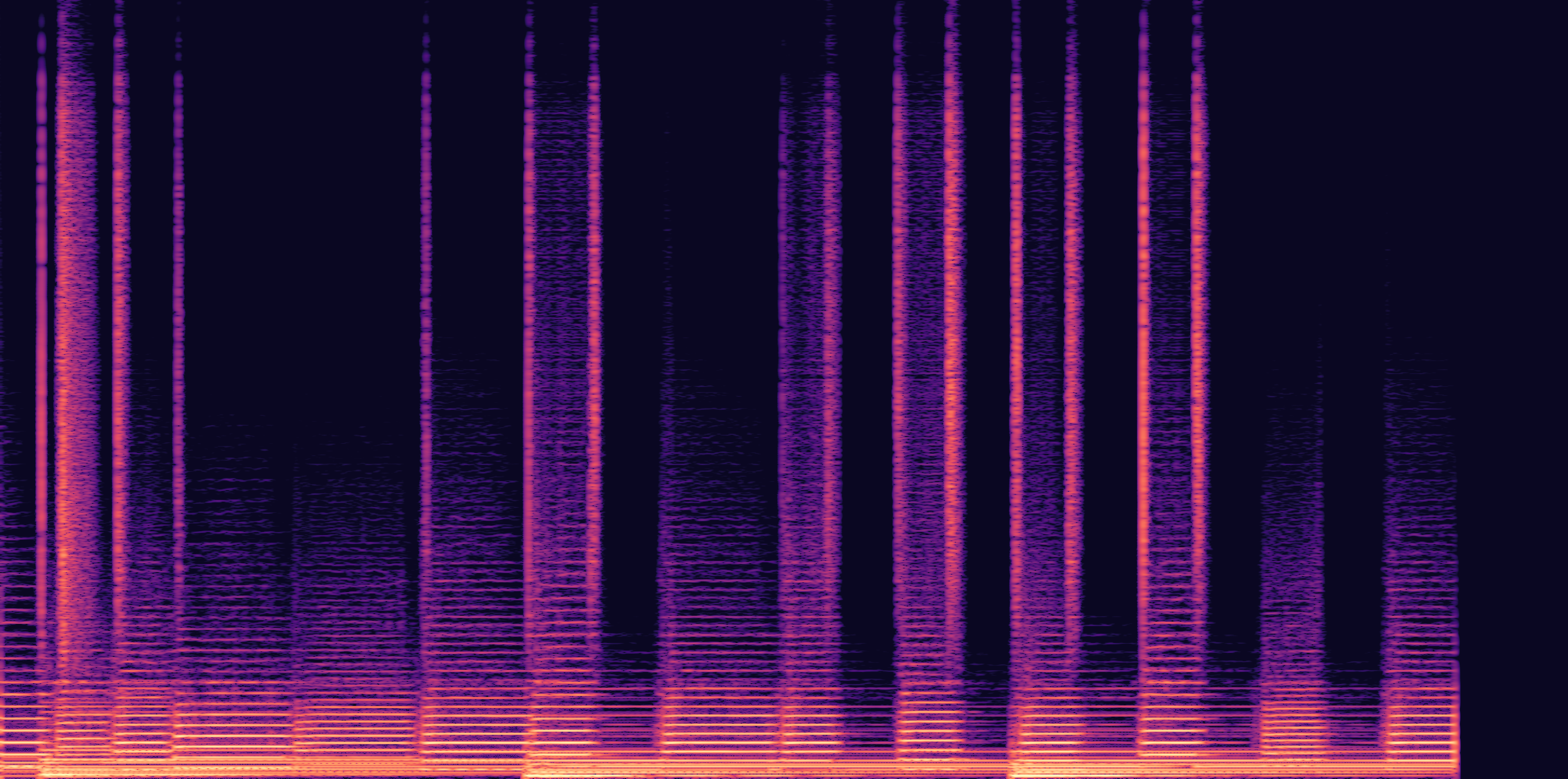
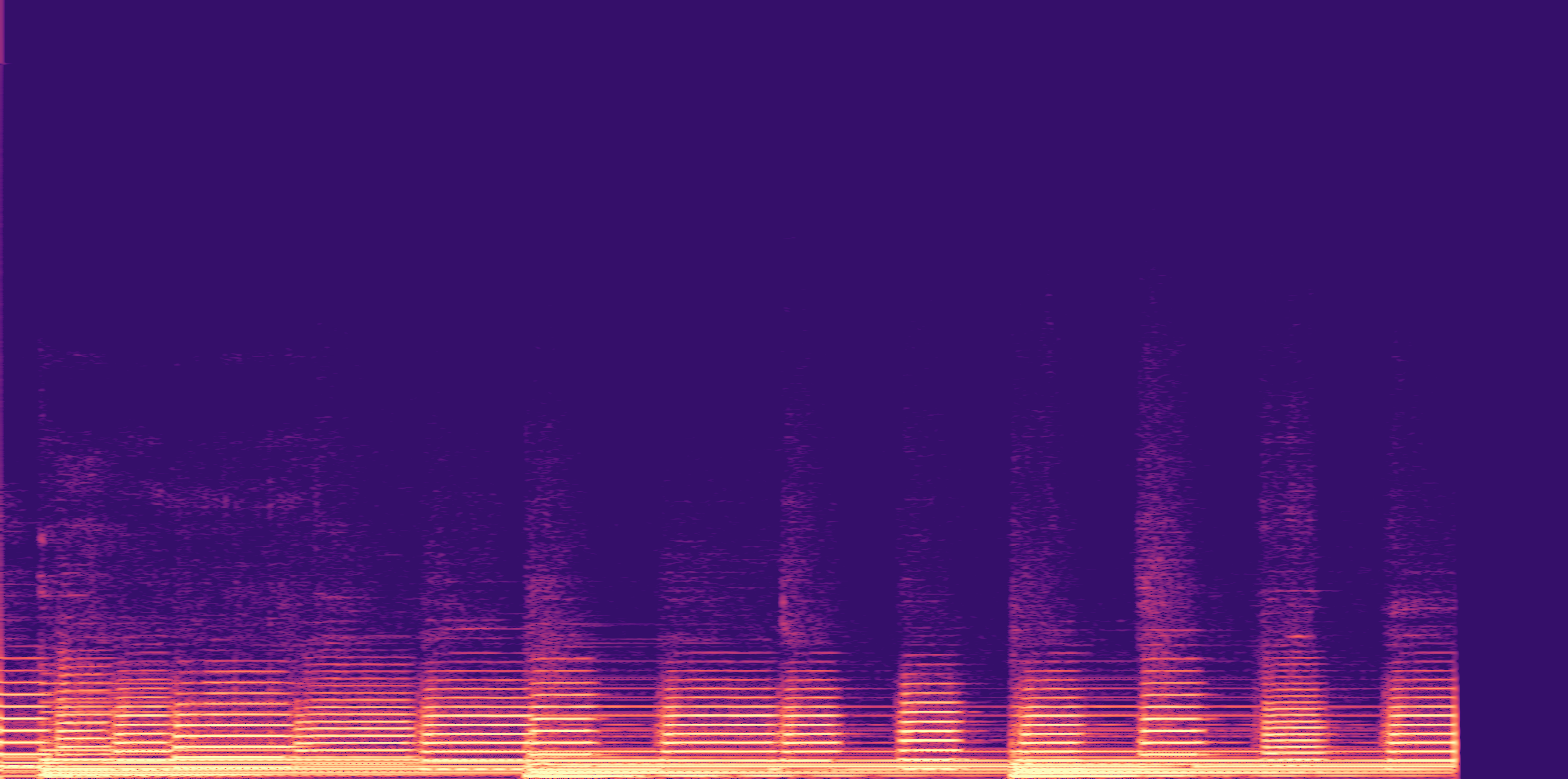
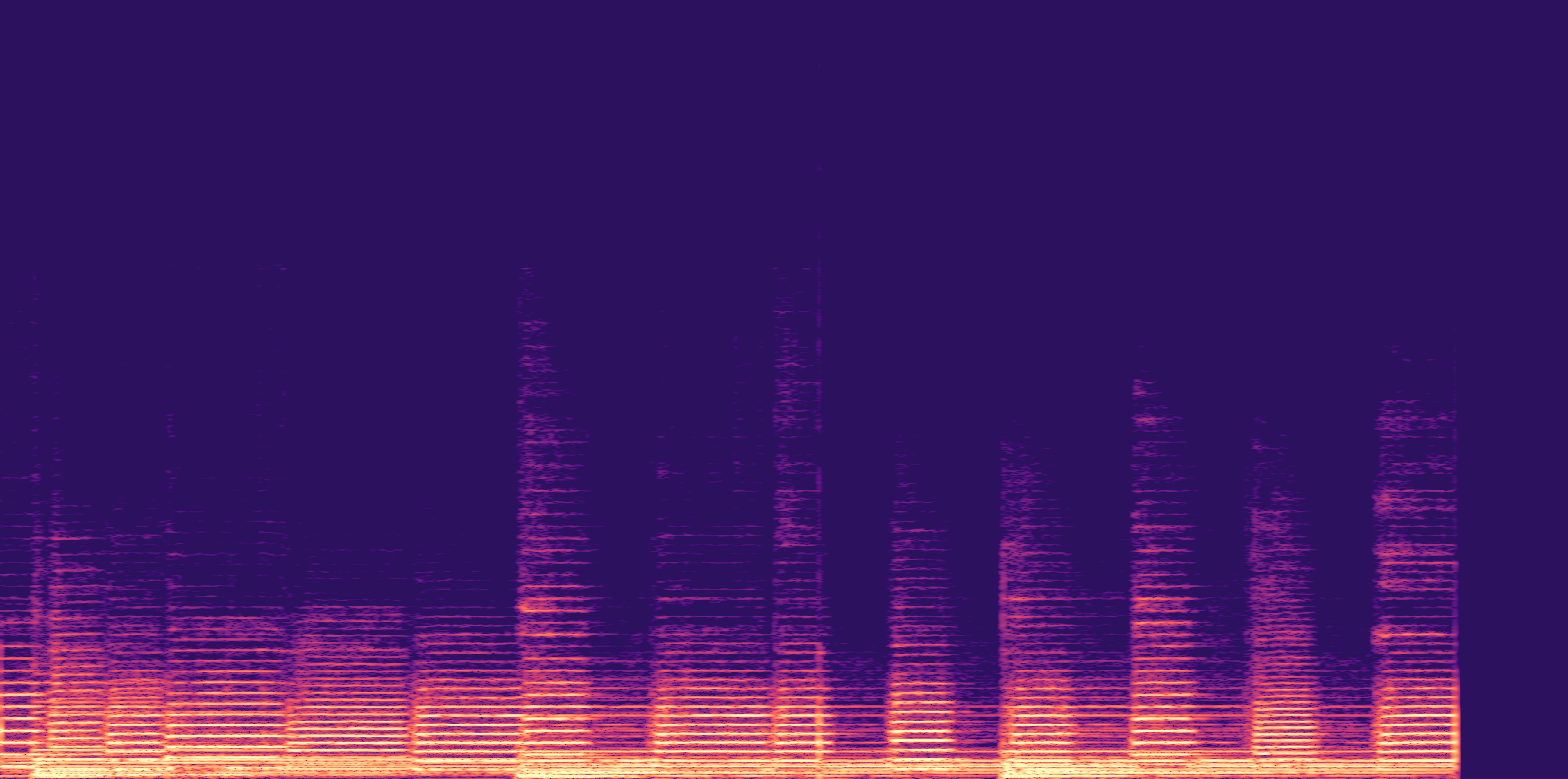
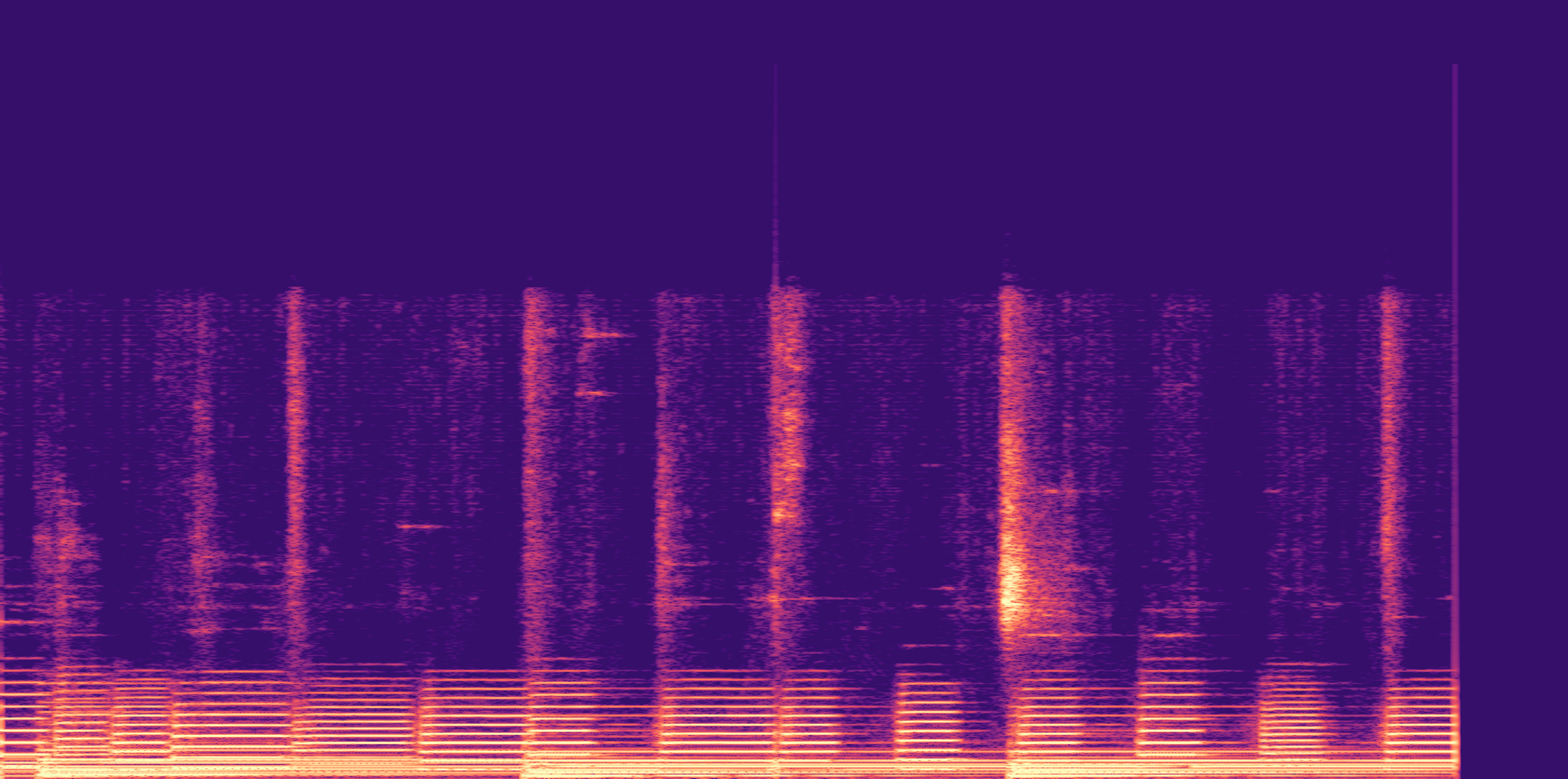
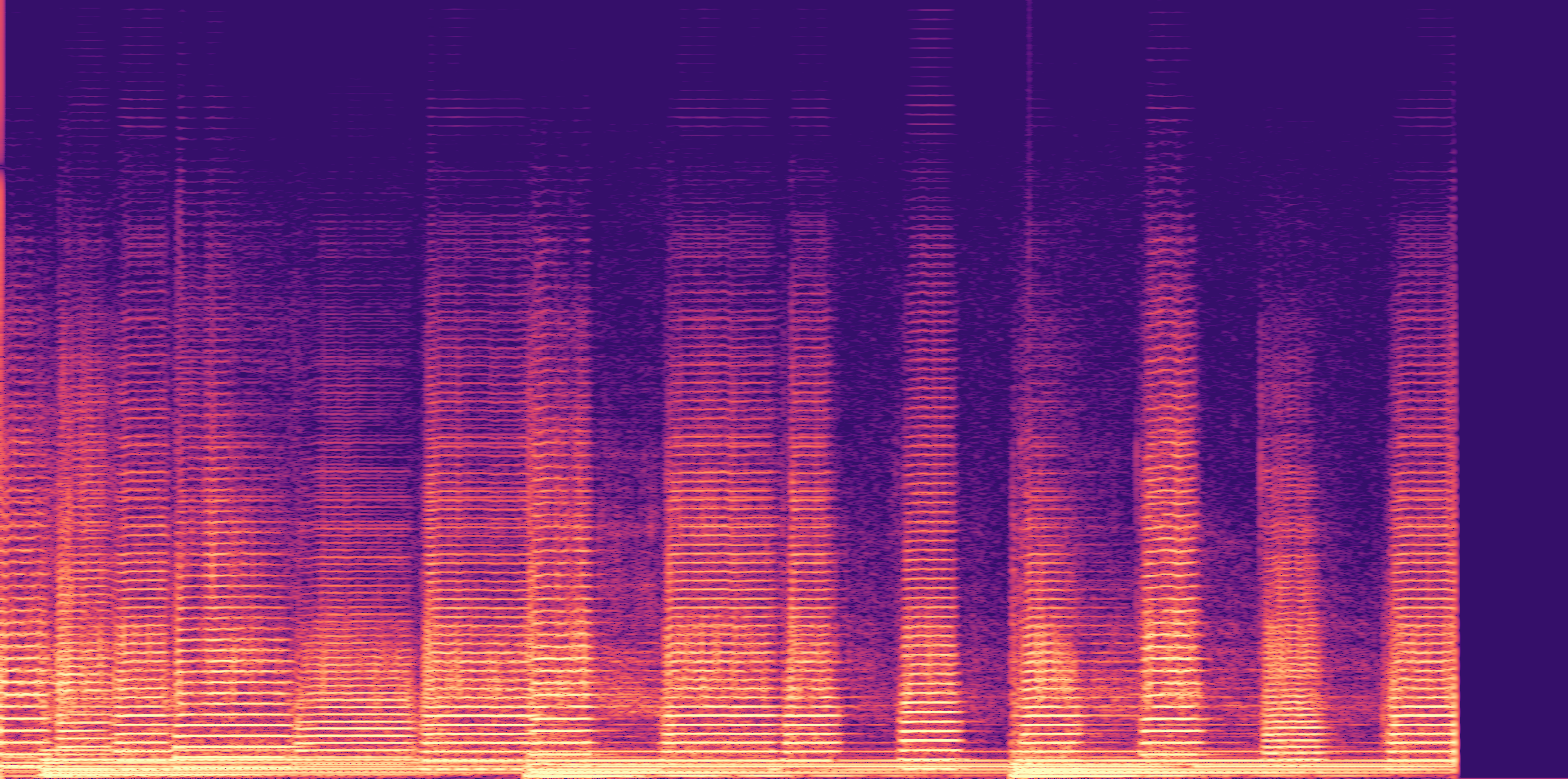
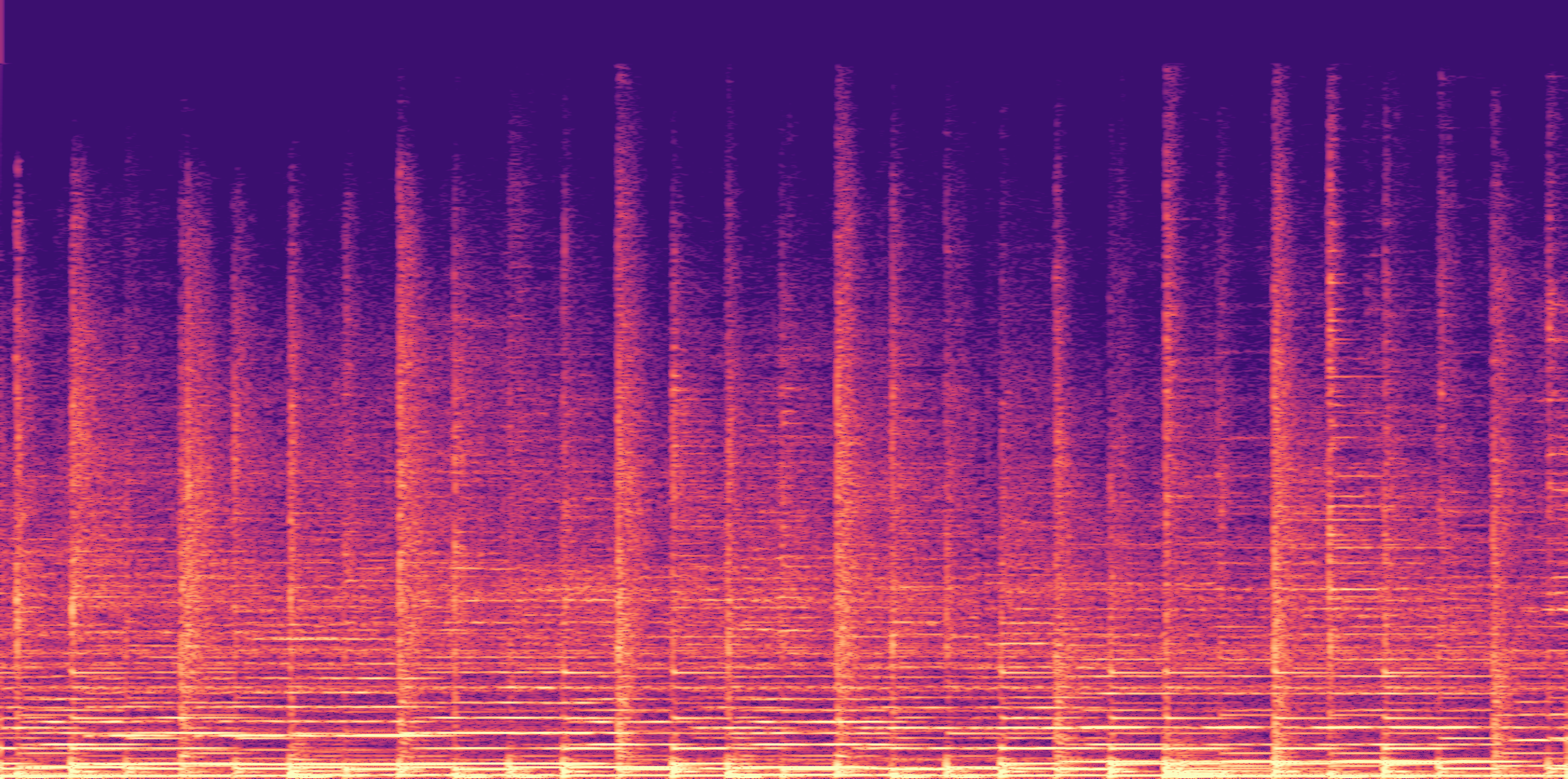
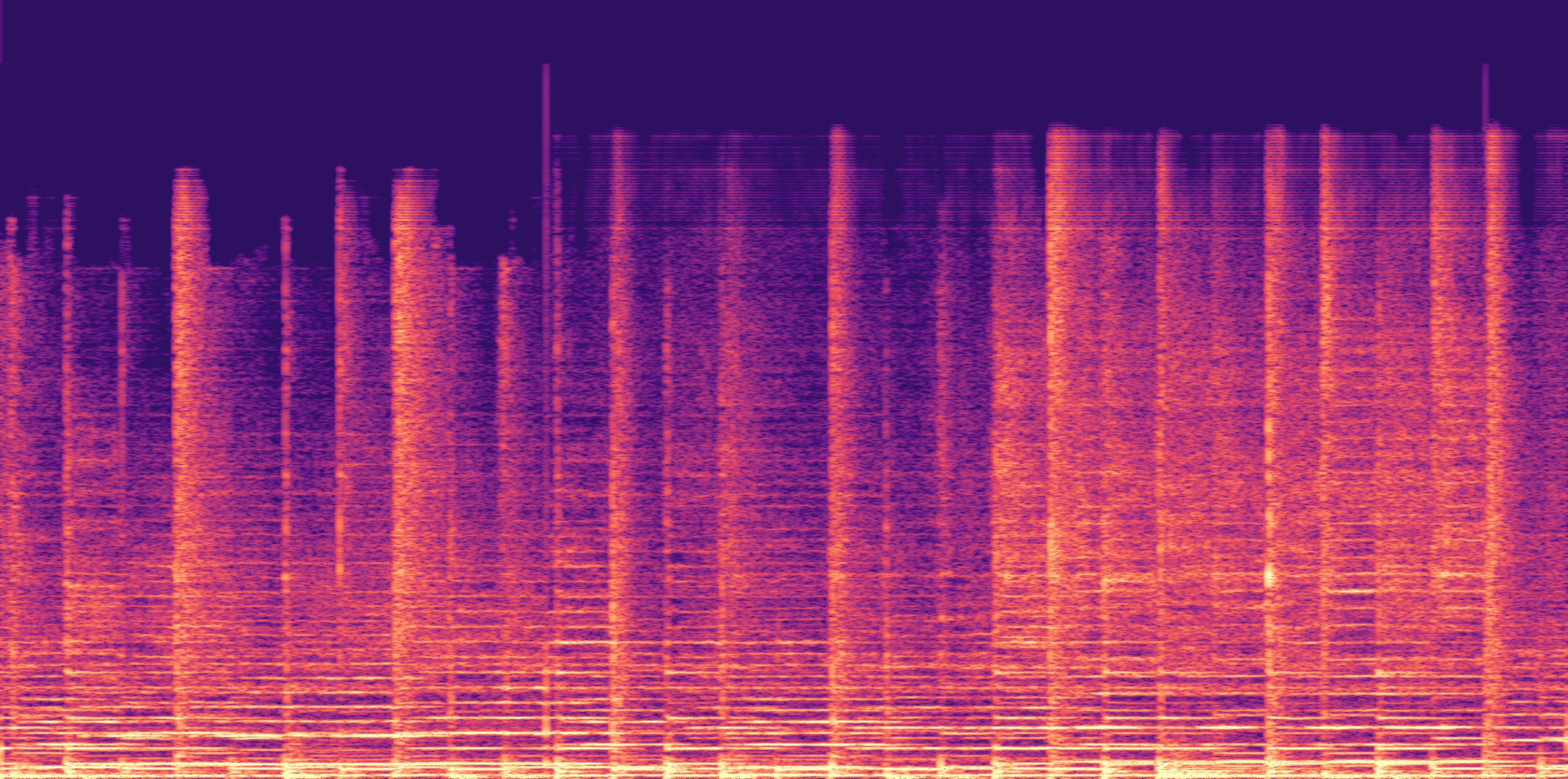
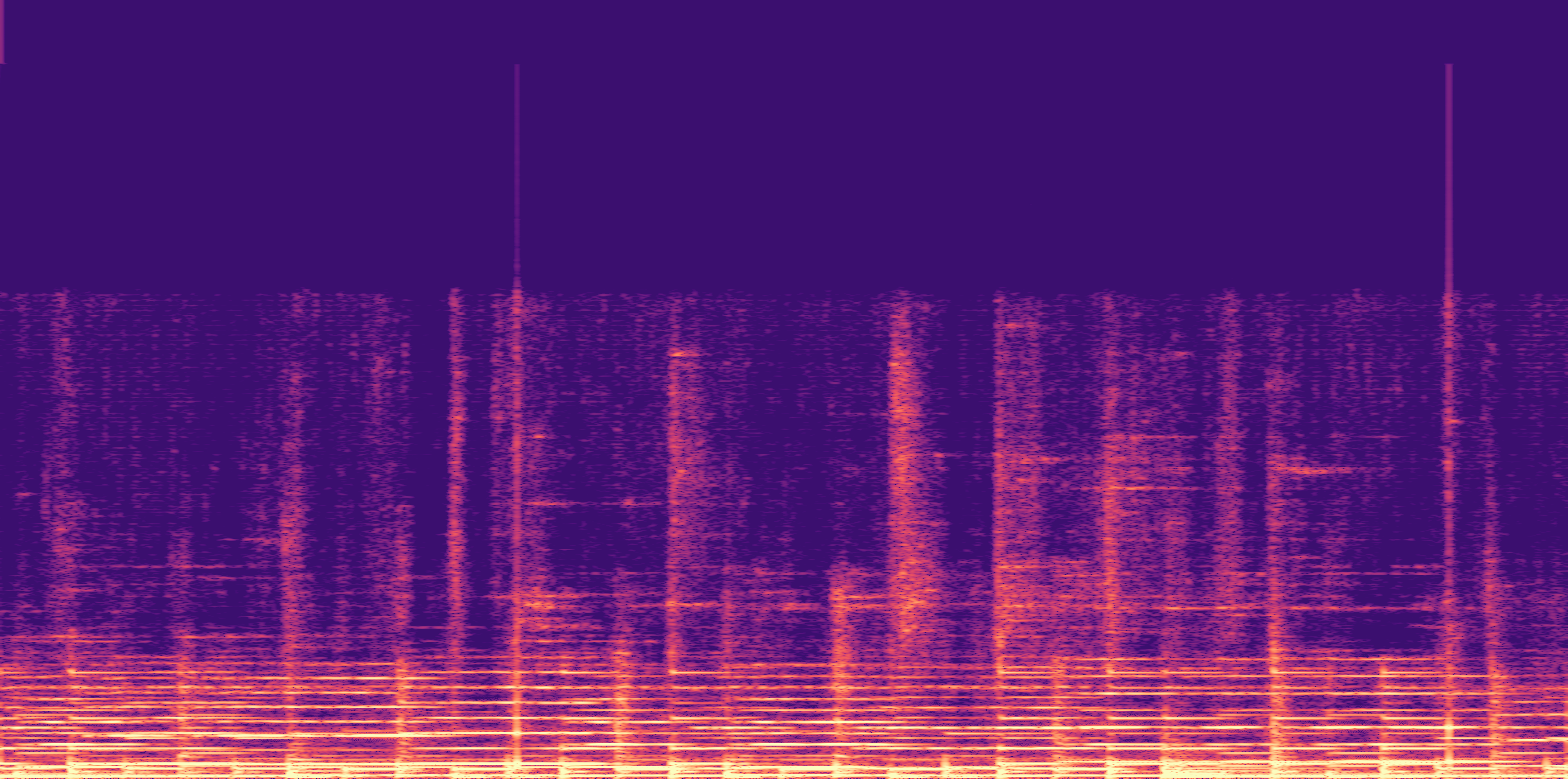
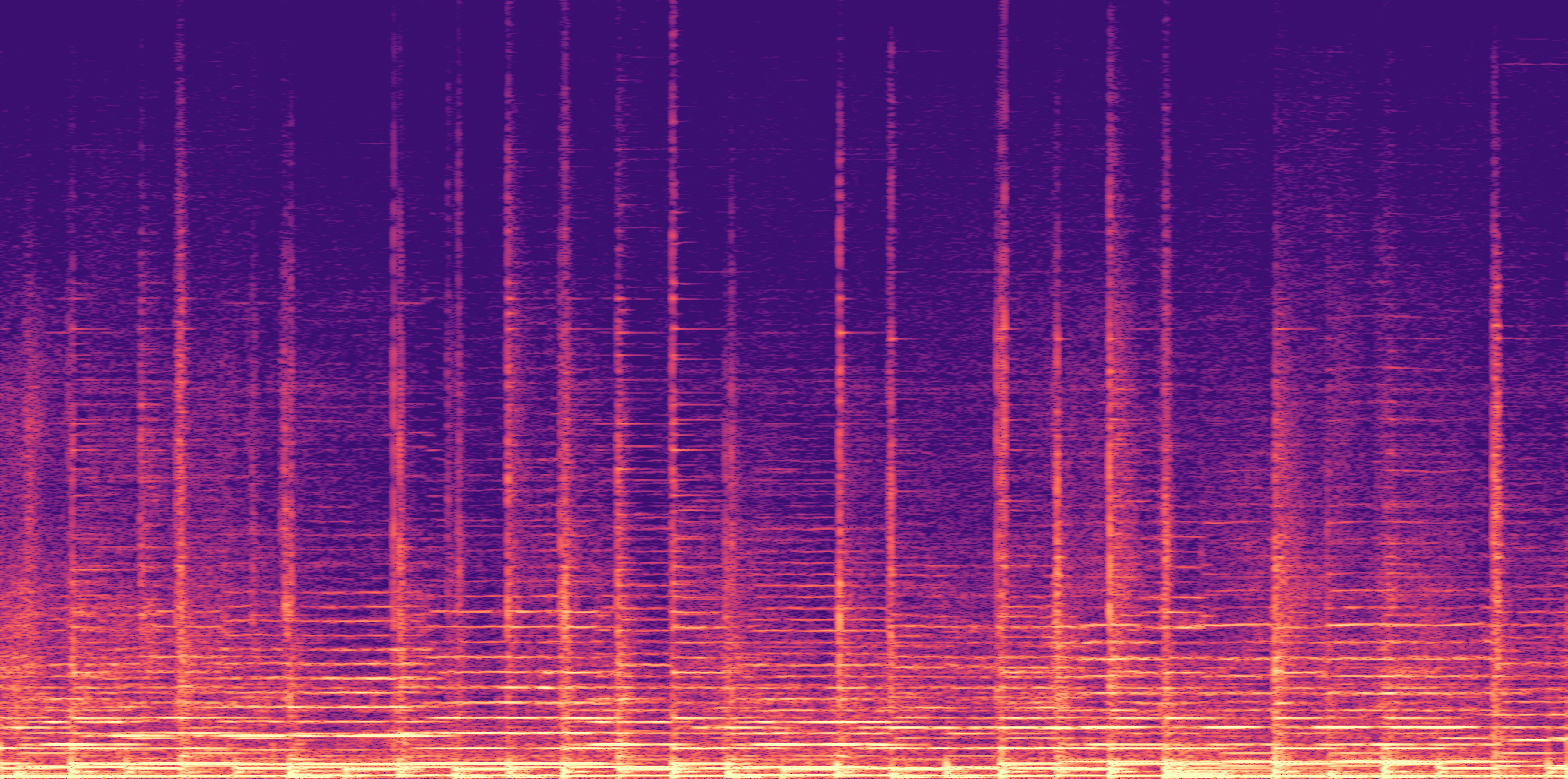
ESC-50, 8kHz input
Low

Ours

AudioSR

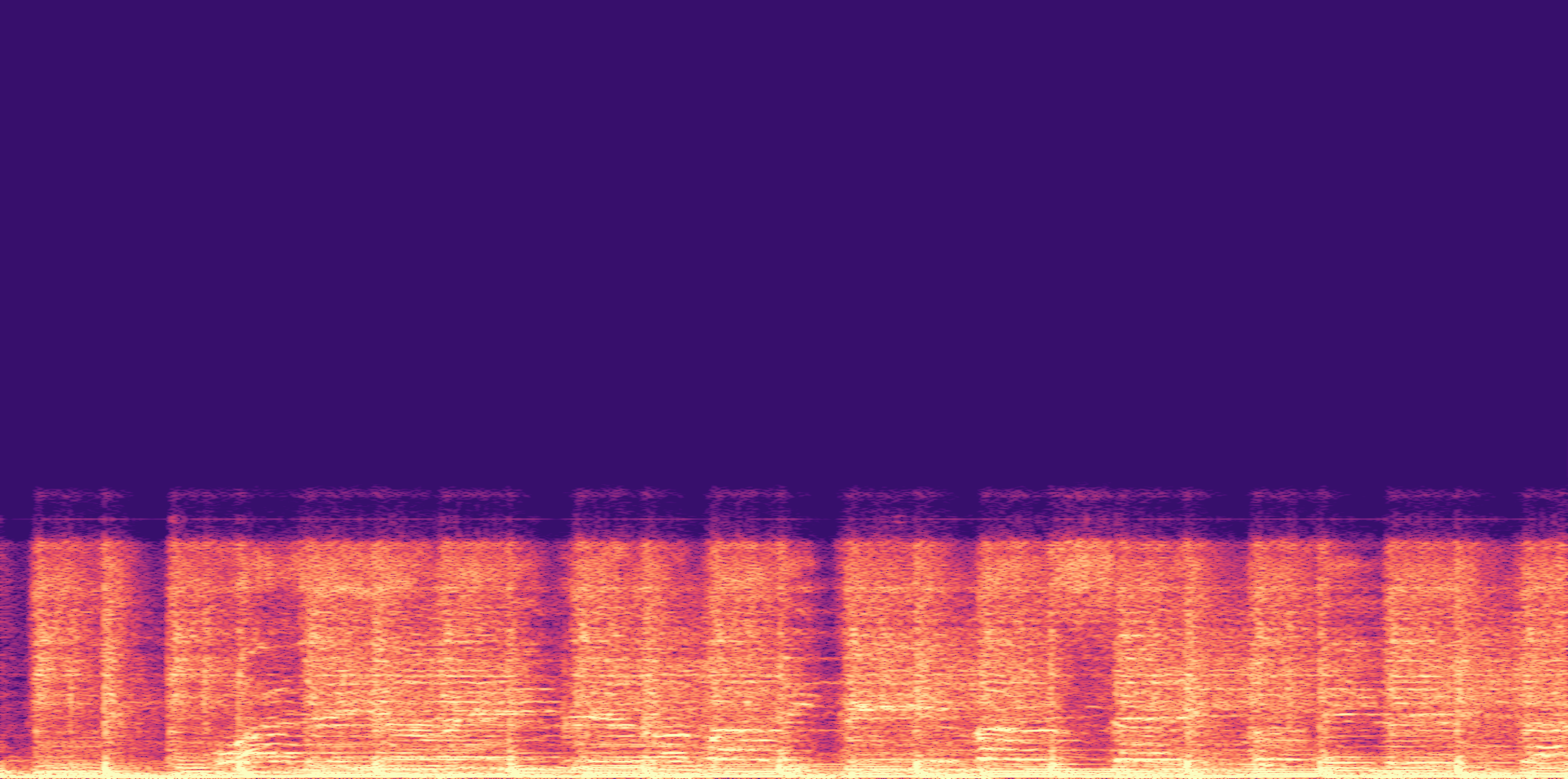
Low
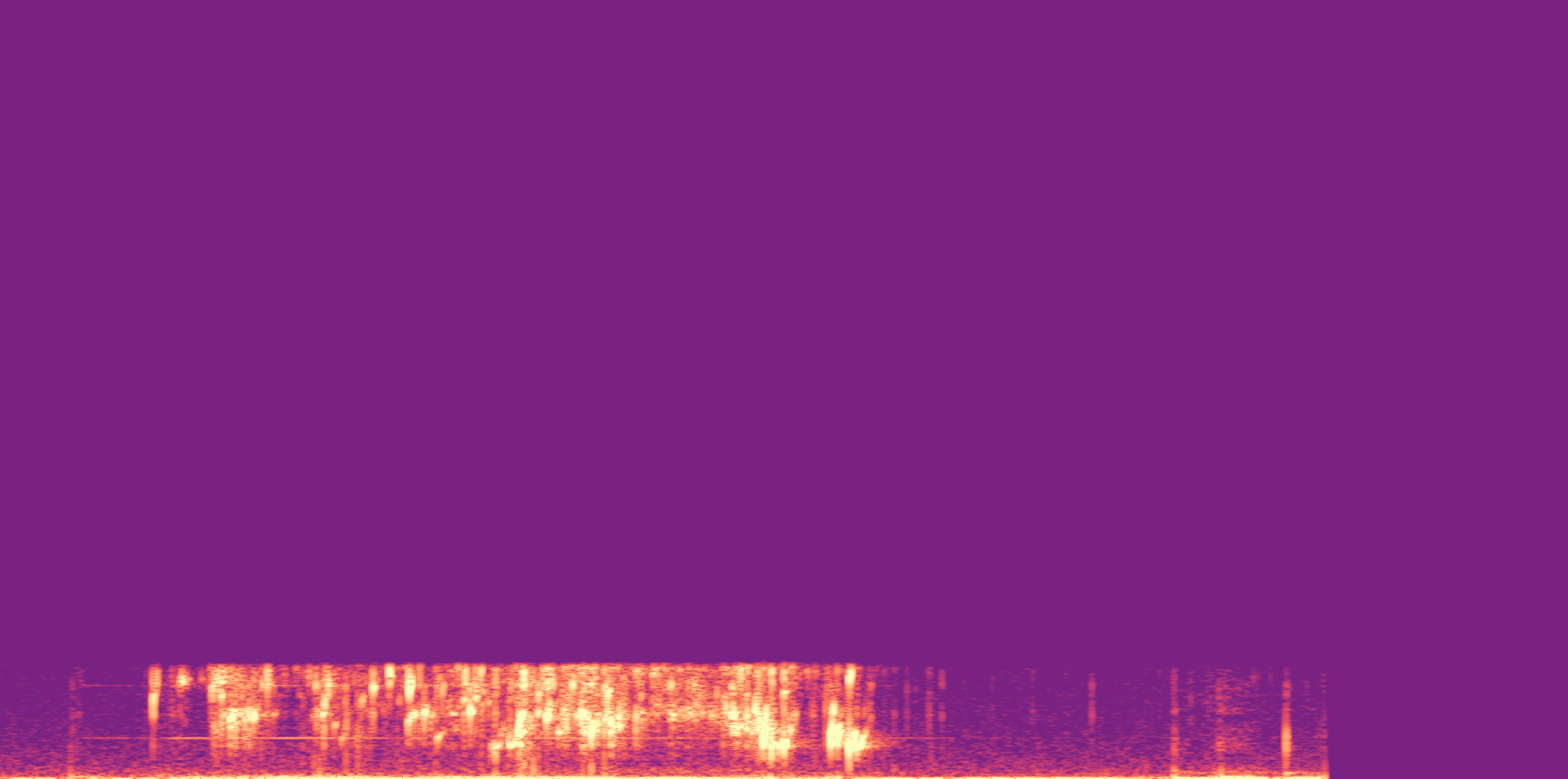
Ours
AudioSR
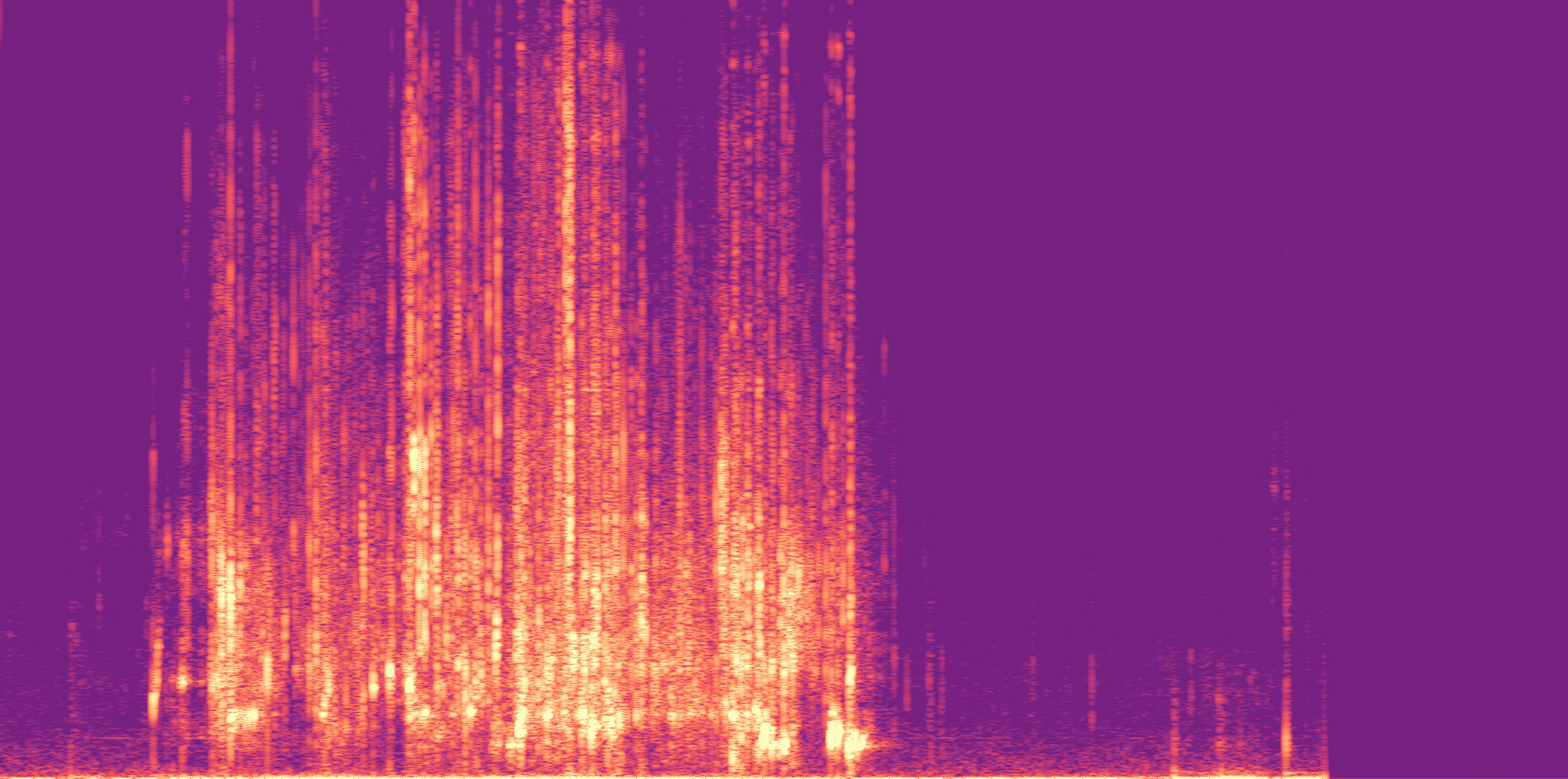
Low

Ours
AudioSR
1 Department of CST, Tsinghua University, Beijing, China
2 Shengshu AI, Beijing, China
3 USTC, Hefei, China
1 {zhc23thuml, liyuanwang, dcszj}@tsinghua.edu.cn
3 lc_lca@mail.ustc.edu.cn
Audio super-resolution (SR), i.e., upsampling the low-resolution (LR) waveform to the high-resolution (HR) version, has recently been explored with diffusion and bridge models, while previous methods often suffer from sub-optimal upsampling quality due to their uninformative generation prior. Towards high-quality audio super-resolution, we present a new system with latent bridge models (LBMs), where we compress the audio waveform into a continuous latent space and design an LBM to enable a latent-to-latent generation process that naturally matches the LR-to-HR upsampling process, thereby fully exploiting the instructive prior information contained in the LR waveform. To further enhance the training results despite the limited availability of HR samples, we introduce frequency-aware LBMs, where the prior and target frequency are taken as model input, enabling LBMs to explicitly learn an any-to-any upsampling process at the training stage. Furthermore, we design cascaded LBMs and present two prior augmentation strategies, where we make the first attempt to unlock the audio upsampling beyond 48 kHz and empower a seamless cascaded SR process, providing higher flexibility for audio post-production. Comprehensive experimental results evaluated on the VCTK, ESC-50, Song-Describer benchmark datasets and two internal testsets demonstrate that we achieve state-of-the-art objective and perceptual quality for any-to-48 kHz SR across speech, audio, and music signals, as well as setting the first record for any-to-192kHz audio SR.
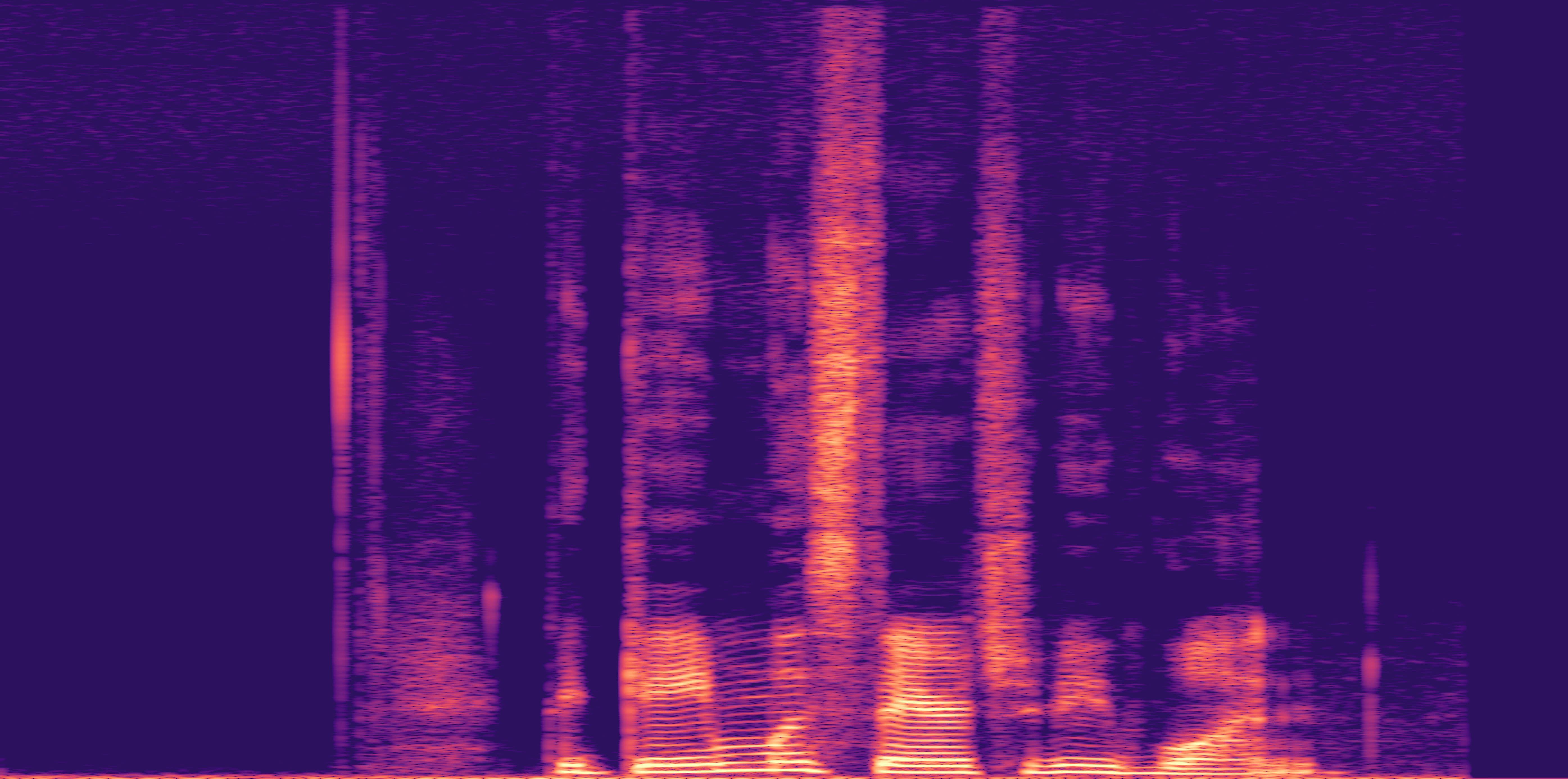
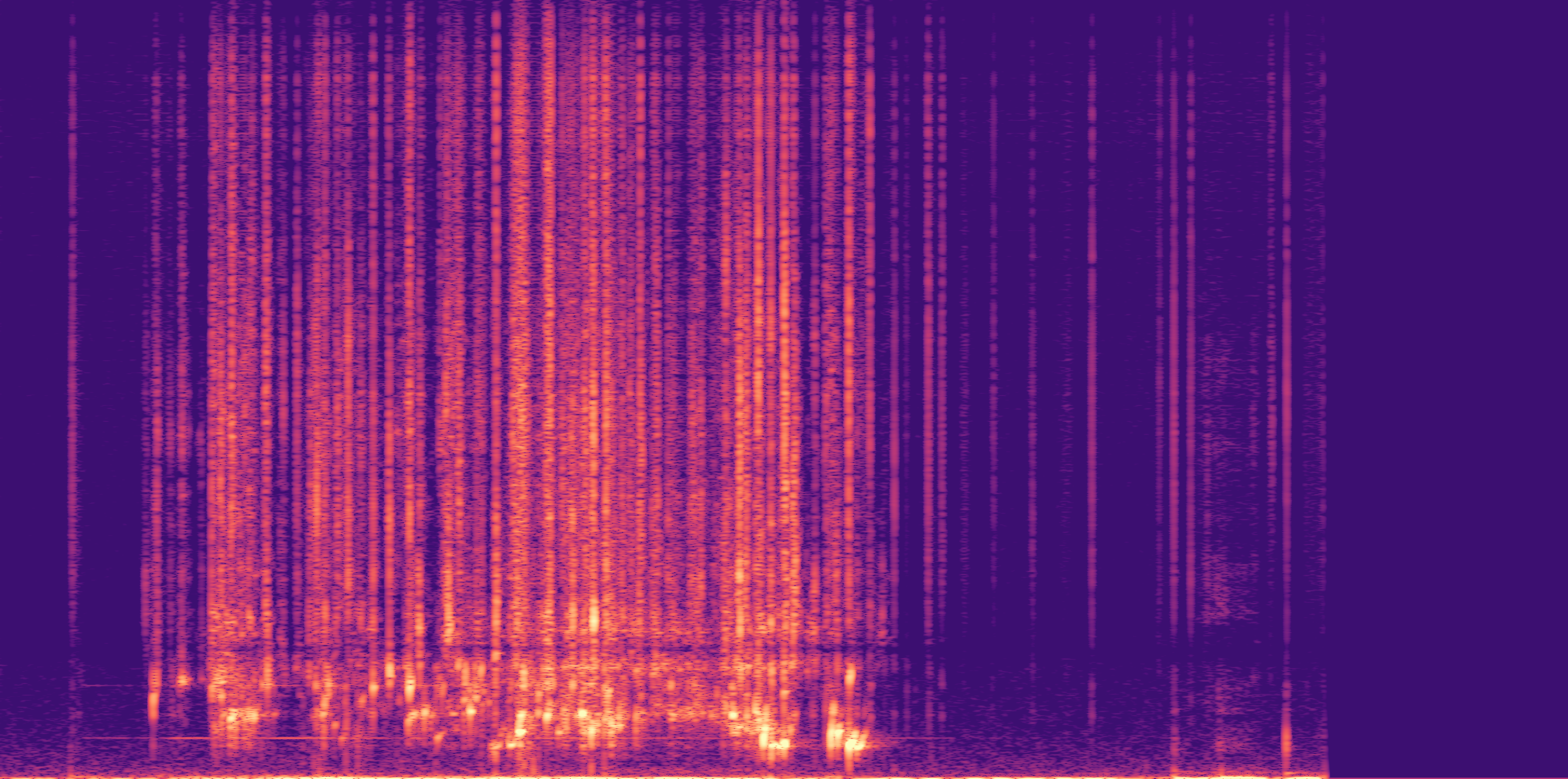
Low
Ours
AudioSR
Low
Ours
AudioSR
Low
Ours
AudioSR
Low
Ours
AudioSR
Low (Volume may be high)
Ours (Volume may be high)
AudioSR (Volume may be high)
Low
Ours
AudioSR
Low
Ours
AudioSR
Low
Ours
AudioSR
Low
Ours
AudioSR
Low
Ours
AudioSR
Low
Ours
AudioSR
Low
Ours
AudioSR
Ground Truth
Input
Nu-Wave2
NVSR
Frepainter
Flowhigh
AudioSR
Ours
Ground Truth
Input
Nu-Wave2
NVSR
Frepainter
Flowhigh
AudioSR
Ours
Low
Ours
AudioSR
Low
Ours
AudioSR
Low
Ours
AudioSR
Low
Ours
AudioSR
Low
Ours
AudioSR
Low
Ours
AudioSR
Low
Ours
AudioSR
Low
Ours
AudioSR
Low
Ours
AudioSR
Input
AudioSR
A2SB
AUDIT
CQTDiff
Ours
Input
AudioSR
A2SB
AUDIT
CQTDiff
Ours